TideSQL v4.5.5 & InnoDB Full-Text Search, Spatial, and Large Value Analysis in MariaDB v11.8.6

published on June 4th, 2026
Most don’t know but TideSQL has geo-spatial and full-text search support thus in today’s analysis I used exfbench (extra functionality (exf)) to run those features through a benchmark with an additional large value benchmark. If you don’t know TideSQL is a plugin for MariaDB in which is powered by TidesDB.
The specs for the environment are
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
- GCC
- jemalloc
- TideSQL v4.5.5, TidesDB v9.3.4, MariaDB v11.8.6
Both engines live inside the same MariaDB server and exfbench hands each of them byte for byte identical SQL, changing only the ENGINE clause, so whatever differences show up belong to the storage engine and not to the schema or the query. Every workload runs the same way. It creates the table with just a primary key, bulk loads it, builds the index as its own separately timed step, runs ANALYZE TABLE, and then runs the query suite while recording p50 through p99 latency and QPS. Afterward each table is compacted with OPTIMIZE TABLE and its real on-disk size is measured with du.
The setting that turned out to matter most was the cache. I gave InnoDB a 512MB buffer pool and TidesDB a 512MB block cache. That is deliberately small. It is comfortably larger than the spatial data, which is around 40MB, and the full-text data, which is a few hundred megabytes, but far smaller than the 5GB of large values, which means large value reads have to come off the SSD rather than out of RAM. Durability was relaxed evenly on both sides so that neither engine pays an fsync tax the other avoids. InnoDB ran with flush_log_at_trx_commit set to 2, doublewrite off, and O_DIRECT_NO_FSYNC, while TidesDB ran with its sync modes set to none. Compression was off everywhere. TidesDB ships a skip_unique_check flag because checking primary key uniqueness on an LSM costs a read before every write, and since InnoDB has no startup equivalent I set unique_checks and foreign_key_checks to zero globally so the loads stay on equal footing.
Then I ran the whole thing twice, changing only how the measured queries pick their keys. The first pass, which I will call zipfian, hammers a small hot set so most reads land in cache, which is roughly what a real OLTP workload looks like. The second pass, uniform, spreads reads evenly across every key so the cache is constantly missed and the engine’s on-disk read path gets exercised in full. The distance between those two passes ended up being the most interesting result of the whole exercise.
A word on what sits behind each number before we get to them. Every query type runs a fixed batch of measured operations after a warmup that gets thrown away, and the percentiles come from that batch. The spatial and full-text suites use five thousand measured queries per type after two hundred warmup queries, and the large value suite uses two thousand after fifty, all single threaded with a fixed seed so the boxes, terms, and keys are reproducible. A p50 or p99 here is the median or 99th percentile of thousands of real operations rather than a handful. I did not run each whole configuration several times and average across runs, so I am not quoting run to run variance directly, but the zipfian and uniform passes happen to agree to within about ten percent on the cache resident spatial and full text workloads, which says the noise floor is small, and the gaps that carry the conclusions, twelve to a hundred times and beyond, are far larger than any plausible wobble.
The bigger caveat is that this is a single threaded latency benchmark, and that is a real limitation rather than a footnote. It measures how long one operation takes for one client, not how either engine behaves under concurrency, and an LSM and a B-tree diverge most exactly where this test stays silent. Put many writers on TidesDB at once and you start paying for compaction stalls, the L0 queue stall threshold, write back-pressure, and, since this configuration runs with pessimistic locking off, optimistic commit conflicts that have to be retried, while InnoDB trades those for row lock waits and buffer pool contention instead. The cnf even exposes those levers, the L0 stall threshold, the flush and compaction thread counts, the locking mode, and none of them get touched by a single client. So read everything below as single client latency, and treat the recommendations at the end as scoped to that.
Loading and building indexes
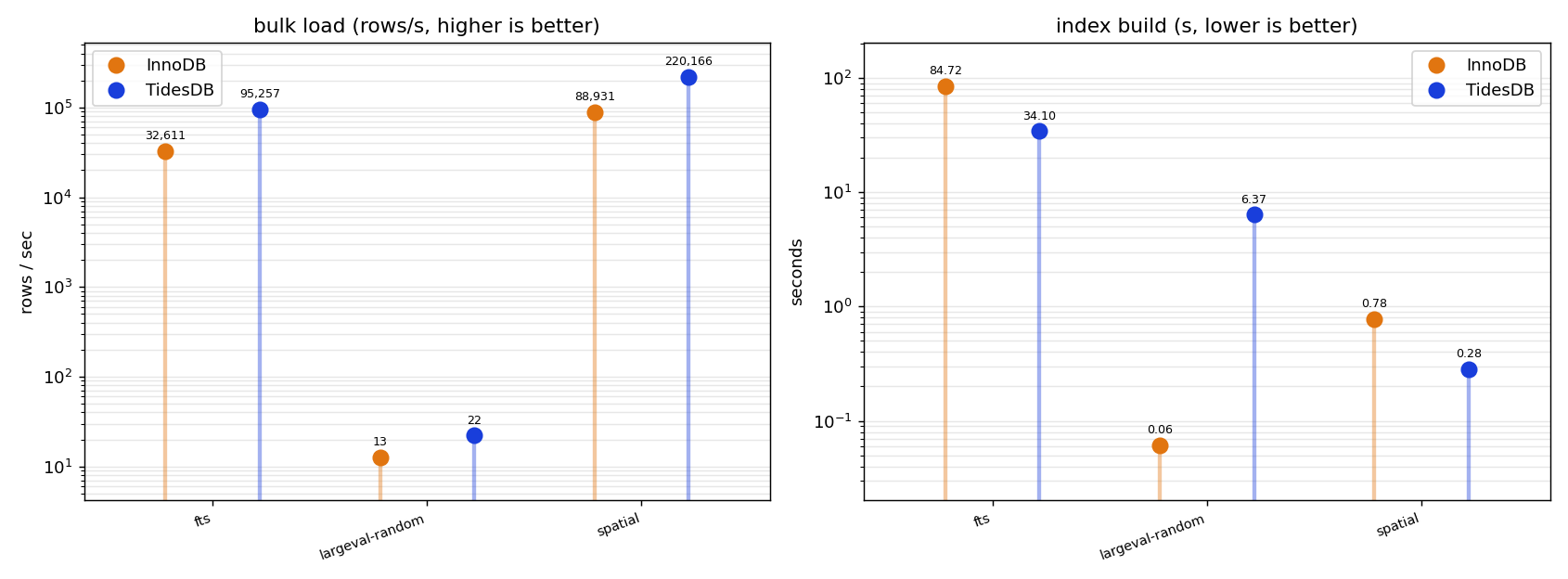
TidesDB is the faster writer almost everywhere. It loaded the GeoNames points at around 221 thousand rows per second against InnoDB’s 178 thousand, ingested the 200 thousand Wikipedia articles two to three times faster, and pushed the 5GB of large values in at 44 MB/s versus InnoDB’s 25. Building the full-text index is where the gap is widest and most repeatable. TidesDB finished the FULLTEXT build in about 34 seconds while InnoDB took 84. The one place InnoDB turns it around is the plain secondary index on the large value table, which it builds almost instantly through its change buffer while TidesDB spends six to twelve seconds materializing a separate index column family. None of this depends on the access pattern since it is all write side work, and the two passes agreed to within noise.
Storage
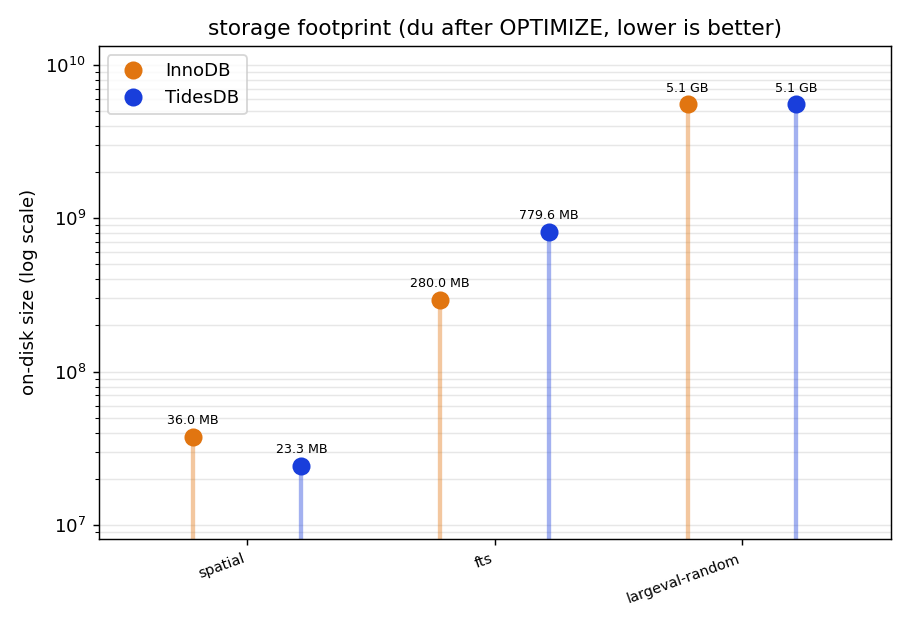
The on-disk picture is mixed and it follows how each engine is built. For the spatial table TidesDB is about half the size of InnoDB. For full-text it is the reverse and then some, with InnoDB at 0.29GB against TidesDB’s 0.82GB, roughly 2.8 times larger, because every FULLTEXT index becomes its own column family keyed by term and primary key, and the load wrote about 1.1GB through TidesDB’s WAL versus 0.63GB of InnoDB redo. For the incompressible large values the two land in a dead heat once compacted, both right around 5.5GB. That last number is a worst case for both since compression was off and the payload was random bytes. A compressible payload with ZSTD or InnoDB page compression would pull them apart and is worth a follow up.
Spatial
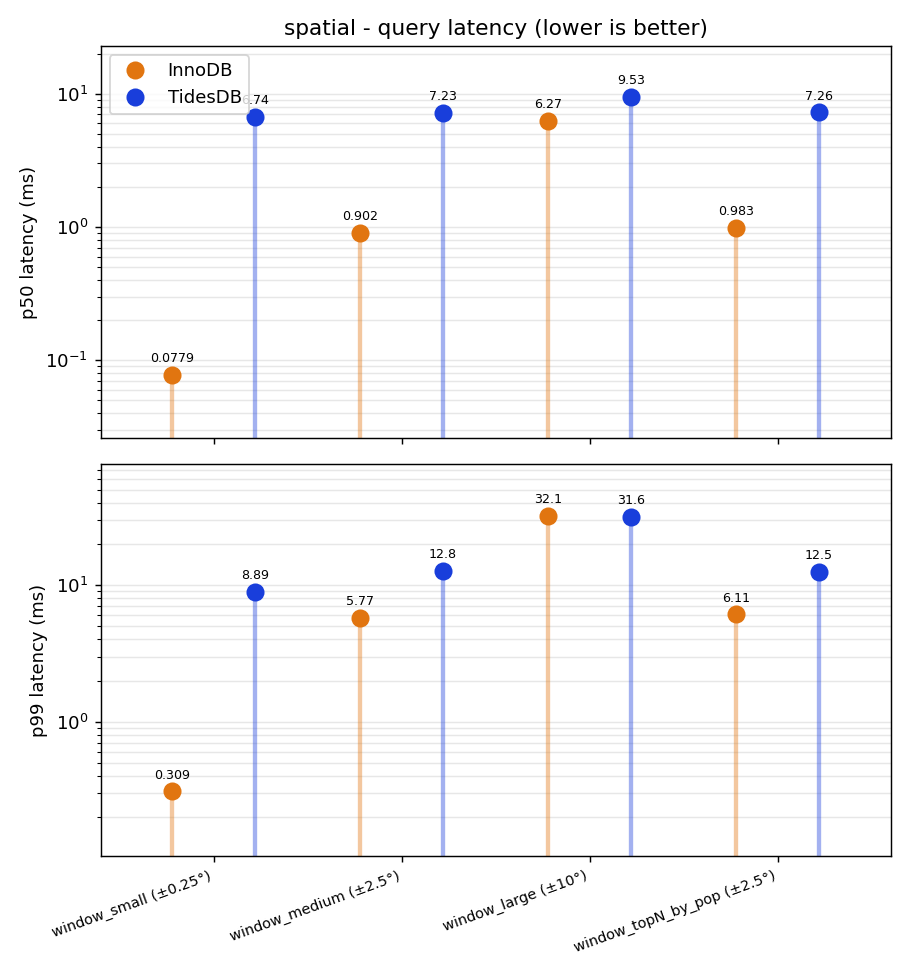
The spatial data fits in cache in both passes, so this is really a test of the in-memory query paths, and InnoDB runs away with it. On the tightest window query InnoDB answers in about 0.07ms while TidesDB needs close to 7, which is roughly a hundred times faster. What the chart shows nicely is the shape of the two curves. InnoDB gets slower as the window grows, from 0.07ms on the small box up to four or six milliseconds on the largest, because its native R-tree prunes hard and only does real work when a lot of rows actually match. TidesDB stays almost flat across every window size, sitting around 7 to 9ms no matter how selective the box is.
That flatness is the tell. TidesDB encodes geometry as a Hilbert curve key inside the LSM, so a bounding box turns into a handful of one dimensional ranges that it walks at a fixed cost regardless of selectivity. EXPLAIN confirms both engines actually use the spatial index, so TidesDB is not silently falling back to a scan, its indexed path is simply heavier for point in rectangle work. The one place they meet is the low selectivity end, where on the largest window the two converge at the tail around 32ms, because once a query has to return a lot of rows anyway InnoDB’s pruning advantage stops mattering. Even losing the read race, TidesDB still loaded the points faster, built the spatial index almost three times faster, and stored the table in half the space.
Full-text search
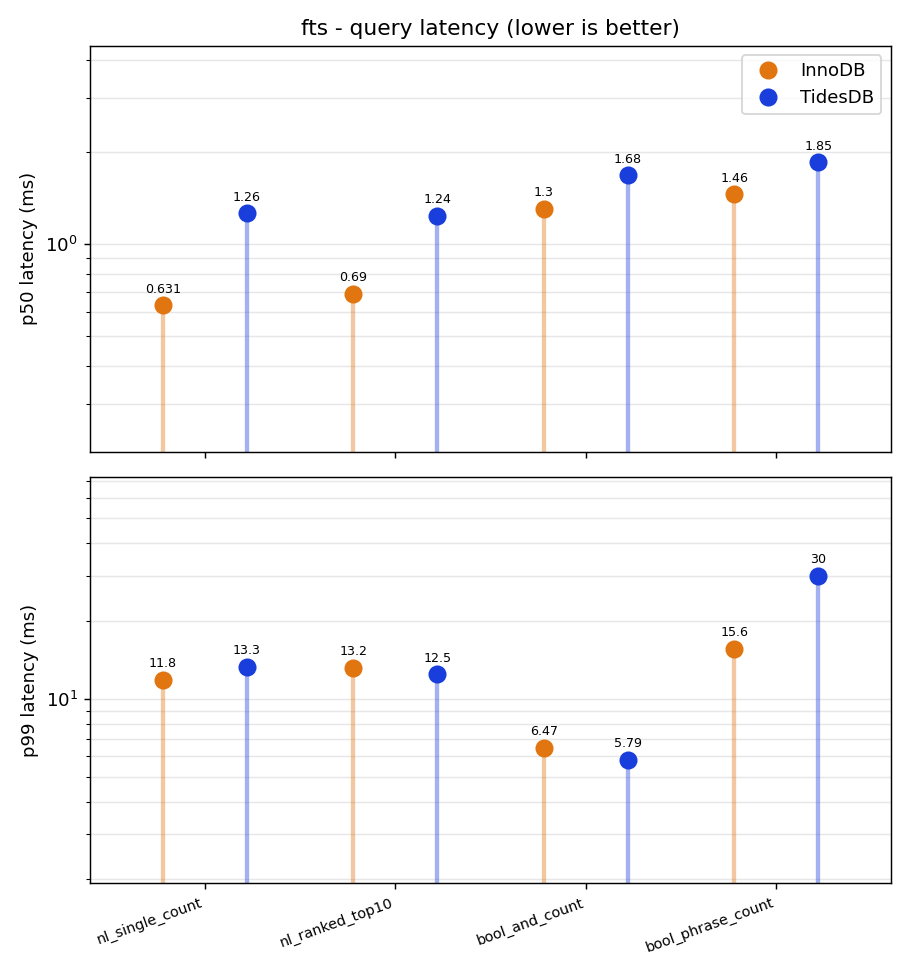
Full-text is the closest matchup and it splits along the line you would expect. TidesDB owns the write side, loading two to three times faster and building the index two and a half times faster as covered above. InnoDB owns most of the read side, answering single term and ranked queries about twice as fast, roughly 0.6ms against 1.3. Boolean AND is basically a tie. The exact phrase query is the only one that flips between the two passes, with TidesDB slightly ahead when more of the data is cached and InnoDB ahead when it is not, and TidesDB’s phrase tail is its soft spot, with a p99 that climbed toward 47ms against InnoDB’s 19. So full-text really does come down to your read to write ratio. Index and ingest heavy work leans TidesDB, query heavy work that also cares about disk footprint leans InnoDB.
Large values
This is the workload the small cache was built to stress and it is where the two passes stop agreeing.
The load and update side already favors TidesDB. It loaded the 5GB about 1.75 times faster because an LSM just appends each 2MB value to its value log sequentially while InnoDB threads every blob through clustered index overflow pages. Rewriting a value tells the same story. When the reads have to come off disk an InnoDB update takes about 55ms because it has to fetch the old overflow pages before rewriting them, while TidesDB finishes in about 34ms by appending a fresh copy.
The read result is the one worth the whole benchmark.
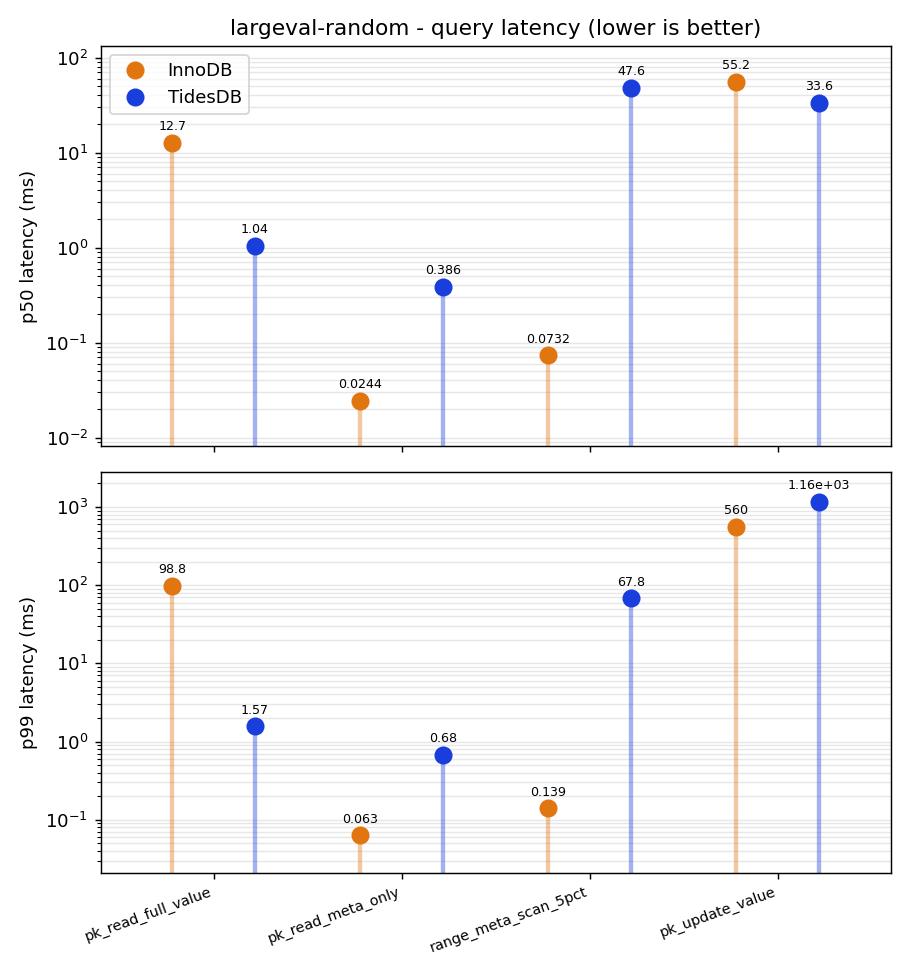
The query that fetches a full 2MB payload by primary key looks almost even when the working set fits in cache. In the zipfian pass InnoDB actually edges it, 0.89ms against 1.02. Then you defeat the cache and the floor drops out from under InnoDB.
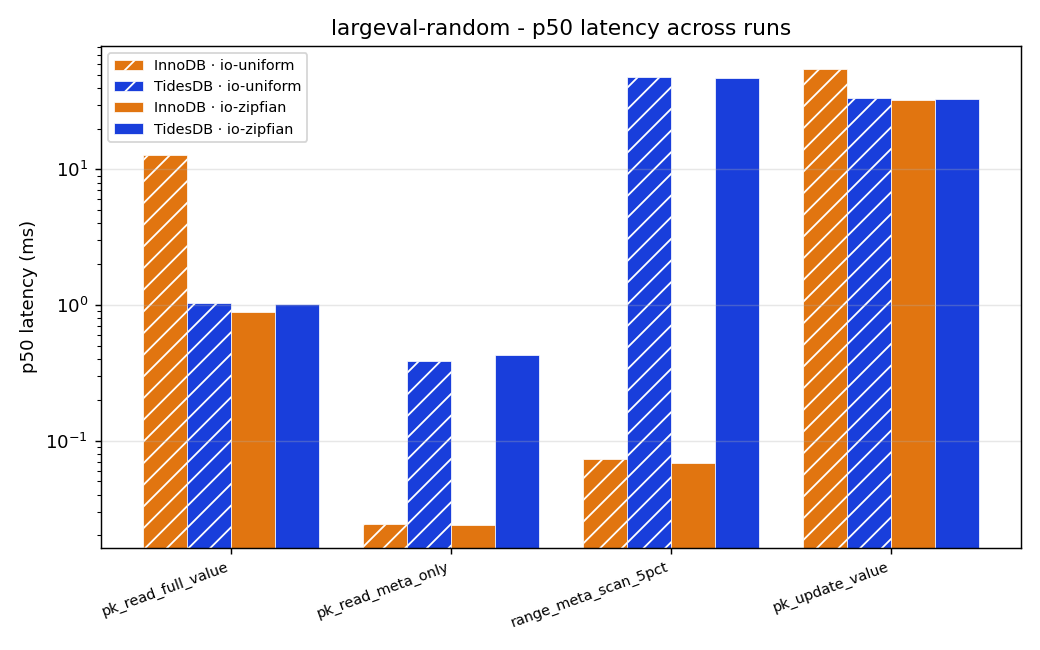
Under uniform access InnoDB’s full value read goes from 0.89ms to 12.7ms, about fourteen times worse, while TidesDB barely moves, from 1.02 to 1.04ms. Once the data no longer fits in memory TidesDB reads large values roughly twelve times faster, and its tail is in another universe, a p99 of about 1.6ms next to InnoDB’s 99. The reason is exactly the key log and value log split that defines an LSM like TidesDB. A cold InnoDB blob read chases a chain of overflow pages scattered off the clustered index leaf, several random page reads for a single value, while TidesDB keeps each value as one contiguous blob in the value log and reads it back with a single seek and a sequential scan, which costs the same whether or not anything is cached. A benchmark that only ran the cache friendly pass would have concluded that InnoDB is at least as fast on large values, and it would have been wrong about the case that matters most.
It is not a clean sweep though, and two queries go hard the other way. Reading only the small metadata columns and skipping the blob stays cheap for both since that data is tiny and cached, but InnoDB does it in 0.024ms against TidesDB’s 0.39, about sixteen times faster, because a clustered index point read of a few columns is simply cheaper than TidesDB’s per lookup path. The secondary index range scan is TidesDB’s worst result in the entire benchmark, 0.07ms for InnoDB versus nearly 48ms for TidesDB, because an LSM range scan over a secondary index has to merge across that index’s memtable and its SSTables while InnoDB just walks a clustered secondary B-tree.
Where each engine lands
Keep the single client framing from earlier in mind for all of this, since these are latency results and not a concurrency study.
If your values are large and your dataset is bigger than memory, TidesDB is the clear pick on these numbers. Its value log separation makes large random reads cache independent and around twelve times faster than InnoDB under disk pressure, its updates are faster for the same reason, and it loads and reindexes noticeably quicker across every workload.
If your working set fits in the buffer pool, InnoDB is hard to beat on reads. An in memory B-tree or R-tree outruns an in memory LSM merge on point lookups, on secondary index range scans, and on spatial window queries, where InnoDB led by anywhere from sixteen to several hundred times.
Full-text sits in the middle, a genuine toss up that tips toward TidesDB if you write and index a lot and toward InnoDB if you mostly read and care about footprint and tail latency.
What none of these recommendations cover is what happens once many clients hit the engine at once, which is precisely where an LSM and a B-tree behave least like their single client selves. Compaction stalls, write stalls, lock waits, and commit retries all live in that regime and this benchmark never enters it. So take the above as how each engine reads and writes when nothing else is competing for it, a strong signal for latency bound work, and worth confirming under your own concurrency before you commit to either.
That’s all for now.
—
Reproducing
Both passes and all three workloads run from one script, and every run writes machine readable CSV and JSON alongside the charts.
ACCESS=zipfian OUTDIR=results/io-zipfian ./scripts/run-benchmarks.shACCESS=uniform OUTDIR=results/io-uniform ./scripts/run-benchmarks.sh-- script is configurable
python3 scripts/plot.py results/io-uniformpython3 scripts/plot.py --compare results/io-zipfian results/io-uniformcnf:
[mysqld]basedir = /media/agpmastersystem/c794105c-0cd9-4be9-8369-ee6d6e707d68/home/bench/mariadbdatadir = /media/agpmastersystem/c794105c-0cd9-4be9-8369-ee6d6e707d68/home/bench/mariadb/dataport = 3306socket = /tmp/mariadb.sockuser = agpmastersystempid-file = /media/agpmastersystem/c794105c-0cd9-4be9-8369-ee6d6e707d68/home/bench/mariadb/data/mariadb.pidlog-error = /media/agpmastersystem/c794105c-0cd9-4be9-8369-ee6d6e707d68/home/bench/mariadb/data/mariadb.errinit_file = /media/agpmastersystem/c794105c-0cd9-4be9-8369-ee6d6e707d68/home/bench/mariadb/init.sql
bind-address = 127.0.0.1max_connections = 1024thread_cache_size = 32table_open_cache = 2048open_files_limit = 65536
skip-log-bin
default_storage_engine = InnoDBdefault_tmp_storage_engine = MyISAMtransaction_isolation = READ-COMMITTEDcharacter-set-server = utf8mb4collation-server = utf8mb4_general_ci
slow_query_log = ONslow_query_log_file = /media/agpmastersystem/c794105c-0cd9-4be9-8369-ee6d6e707d68/home/bench/mariadb/data/slow.loglong_query_time = 2
innodb_buffer_pool_size = 512Minnodb_buffer_pool_instances = 1
innodb_log_file_size = 128Minnodb_log_files_in_group = 2innodb_log_buffer_size = 68M
innodb_flush_log_at_trx_commit = 2innodb_doublewrite = OFFinnodb_flush_method = O_DIRECT_NO_FSYNCinnodb_file_per_table = ON
innodb_compression_default = OFFinnodb_read_io_threads = 2innodb_write_io_threads = 2innodb_purge_threads = 2innodb_thread_concurrency = 0innodb_io_capacity = 1000innodb_io_capacity_max = 4000innodb_use_native_aio = 1innodb_adaptive_flushing = 1tmp_table_size = 32Mmax_heap_table_size = 32M
plugin_maturity = gammaplugin_load_add = ha_tidesdb.so
tidesdb_block_cache_size = 512M
tidesdb_unified_memtable = ONtidesdb_unified_memtable_write_buffer_size = 128M
tidesdb_unified_memtable_sync_mode = NONEtidesdb_default_sync_mode = NONEtidesdb_default_compression = NONE
tidesdb_flush_threads = 6tidesdb_compaction_threads = 4
tidesdb_max_open_sstables = 65536
tidesdb_skip_unique_check = ONtidesdb_default_bloom_fpr = 100
tidesdb_pessimistic_locking = OFF
tidesdb_log_level = NONEtidesdb_default_l0_queue_stall_threshold = 20tidesdb_default_l1_file_count_trigger = 10tidesdb_default_tombstone_density_trigger = 5000tidesdb_default_tombstone_density_min_entries = 2048
tidesdb_max_memory_usage = 0
[client]port = 3306socket = /tmp/mariadb.sockdefault-character-set = utf8mb4
[mysqldump]quickmax_allowed_packet = 64M
[mariadb-backup]
[mysqld_safe]malloc-lib=/lib/x86_64-linux-gnu/libjemalloc.so.2Raw data: data-tidesql-v4-5-5-innodb-fts-spatial-and-large-value-analysis-in-mariadb-v11-8-6/io-raw-dat.zip (sha256: 35a2d65c4b42484d83be0365896b48cfd74f043512eeaf313fb881d5eb1d4ae1)