Benchmark Analysis on TidesDB v8.4.0 and RocksDB v10.10.1

published on February 15th, 2026
I have been in optimization mode lately, pushing modern hardware to its limits and tracing through long running benchmarks to hunt down stalls under extremely large workloads. During this process, I uncovered a couple of bottlenecks under heavy concurrency.
The first bottleneck was spin waits used during SSTable array cleanup after compactions, and in certain conditions they could devolve into a livelock. This became apparent during a MariaDB benchmarking run that I ran a couple of days ago, comparing TidesDB against InnoDB. Under a highly concurrent read write workload, QPS would periodically drop off sharply.
That gave me a clear direction to investigate. After reproducing the issue locally on the same dedicated server configuration, profiling showed that the stalls were directly tied to those cleanup paths. To fix this, I removed reclamation work from the hot path entirely by implementing deferred retired SSTable array reclamation. Cleanup is now handled asynchronously by the system’s reaper thread, which eliminates the spin waits and restores forward progress under load.
After applying the patch, I re-profiled the workload and the stalls were gone. With the profile clean and the major concurrency issue resolved, I could trust the benchmark results again and move on to improving steady state performance.
From there, I focused on the skip list implementation. Profiling at the instruction level revealed a large number of cache misses. To address this, I implemented fully zero get reads for internal use, cached sentinels in cursors, added prefetching of versions during traversals, and fused next and get operations where possible.
The most impactful change was the introduction of a new skip list arena bump allocator, sized to the column family write_buffer_size*2. Nodes and versions are now allocated from contiguous memory blocks using a single atomic_fetch_add per allocation, which is wait free. All allocations are aligned to 8 bytes. When a block is exhausted, a new block is allocated and linked using an atomic CAS on the current_block pointer. Individual frees are no ops, and memory is reclaimed in bulk when the arena is destroyed.
With the above changes, there were a couple of other bug fixes you can read about on the release page on Github here.
With that groundwork in place, I suspect you are curious about the numbers. Let’s dive in.
Firstly I ran the benchtool runner tidesdb_rocksdb_old.sh a few times on the below environment:
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
- GCC (glibc)
Just to see how the systems performed here and then rebenchmarked on the below environment:
- AMD Ryzen Threadripper 2950X (16 cores 32 threads) @ 3.5GHz
- 128GB DDR4
- Ubuntu 22.04 x86_64
- GCC (glibc)
- XFS raw NVMe(SAMSUNG MZVLB512HAJQ-00000) w/discard, inode64, nodiratime, noatime, logbsize=256k, logbufs=8
In the first environment the results show TidesDB wins 20 out of 22 workloads in the runner which is pretty good. No regressions.
I ran the runner 3 times.
| File Name | Format | SHA256 Checksum |
|---|---|---|
| tidesdb_rocksdb_benchmark_results_20260214_201455.csv | CSV | 32c3da67024fa5c6e88f71c1f4cbf67b7d793067daedfd2671bb63a19ecc338e |
| tidesdb_rocksdb_benchmark_results_20260214_201455.txt | TXT | dc60dc737947bf5feee1db83b87169862a4480b3a3b2cbc1aac7bfb6bcd5042f |
| tidesdb_rocksdb_benchmark_results_20260214_223205.csv | CSV | 807447cbd6902c6b64acade87f62d76017f082ba7c960c2bdac83168ed054336 |
| tidesdb_rocksdb_benchmark_results_20260214_223205.txt | TXT | 00f6ba220587252213b59726325015d9546492b508c771c0b49de96c12fe91c1 |
| tidesdb_rocksdb_benchmark_results_20260214_224223.csv | CSV | 8a2842bdf4ded7d214695a59c141067b44a2f3cc276fc8627be6c16d7e061232 |
| tidesdb_rocksdb_benchmark_results_20260214_224223.txt | TXT | 3adfa86571503612aed8440f51c619df5061972b16f272b86692ac8d1a1a0d98 |
RocksDB does fairly well on single threaded deletes, but when you batch TidesDB pulls ahead.
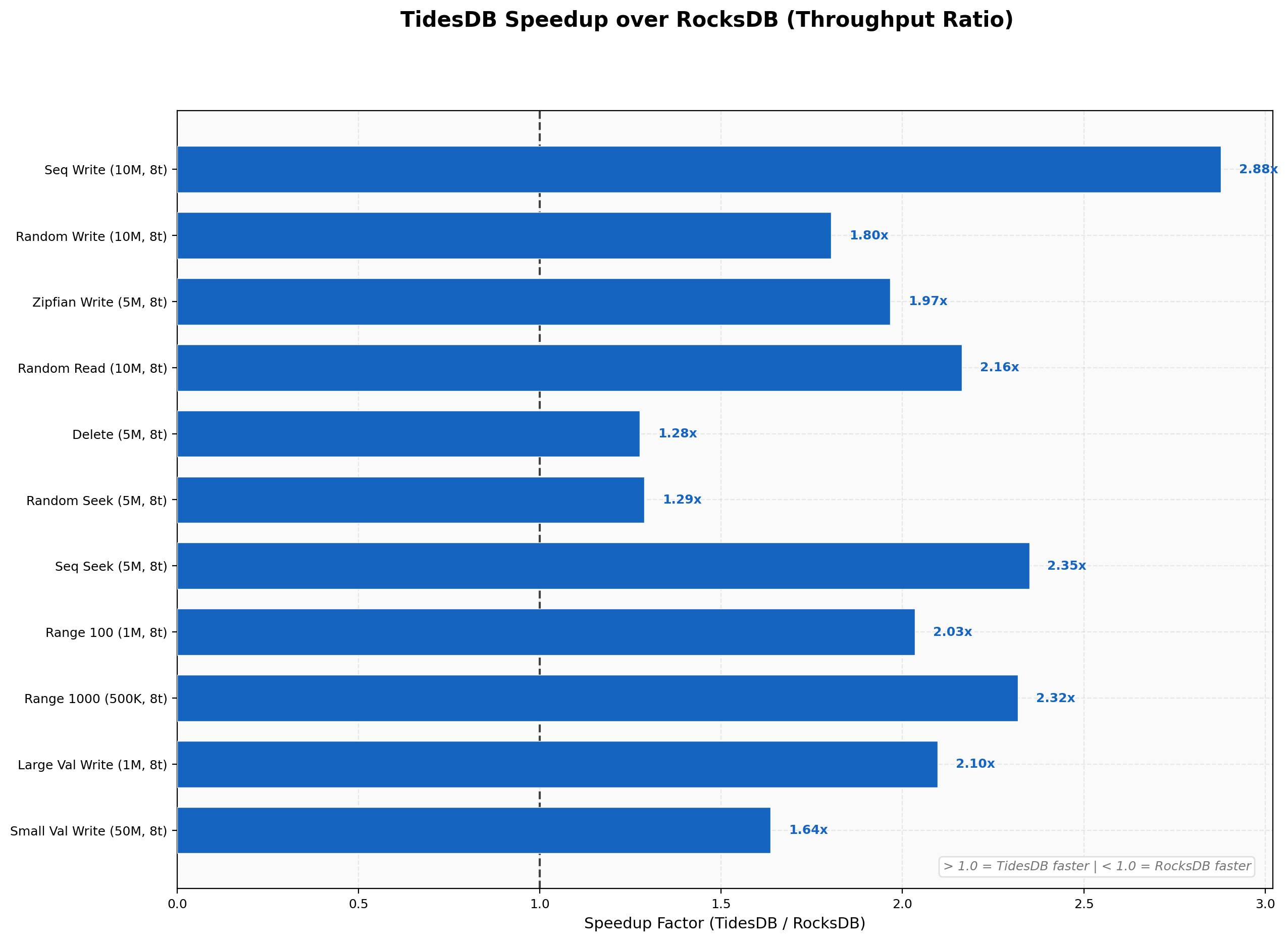
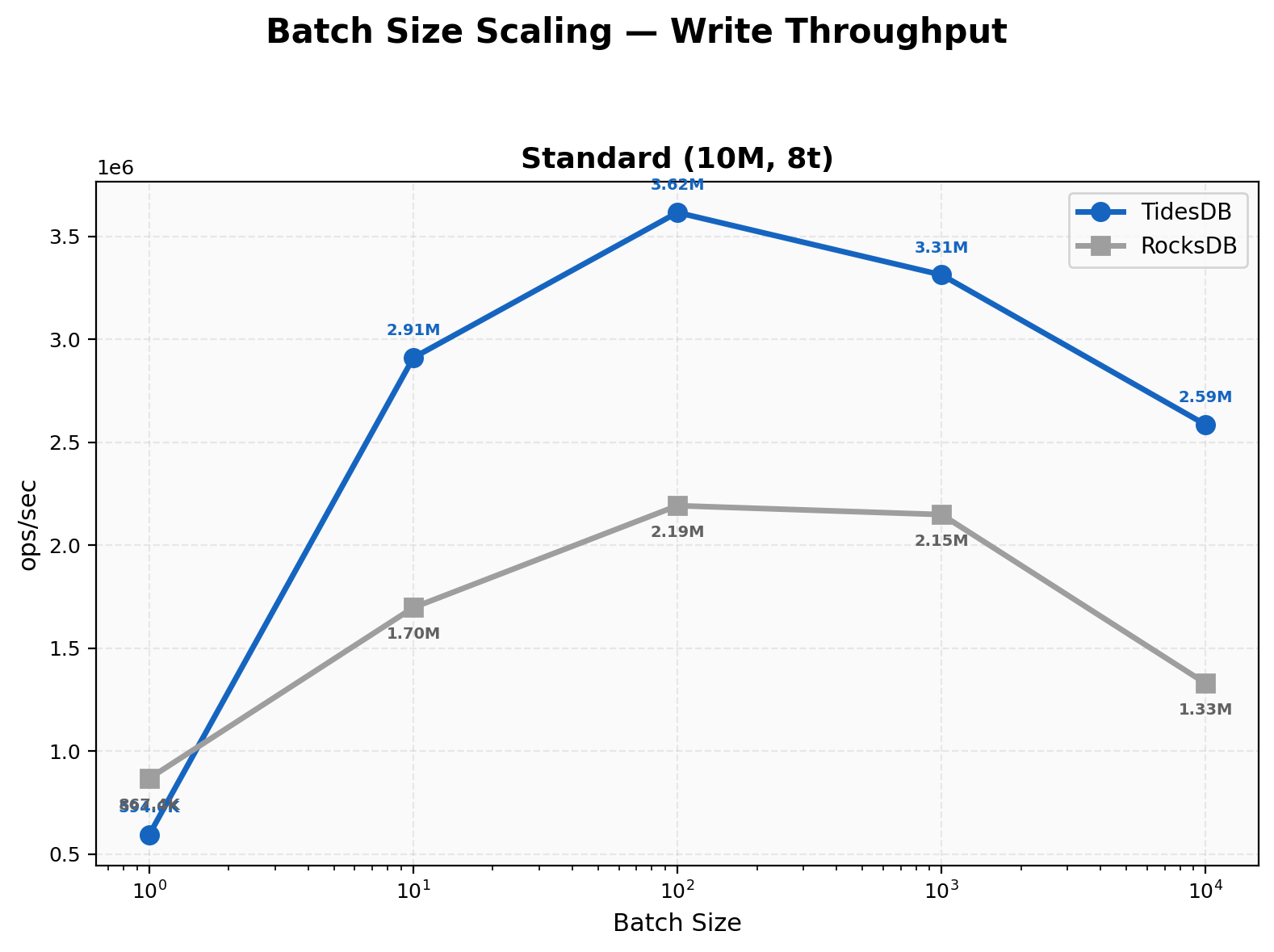
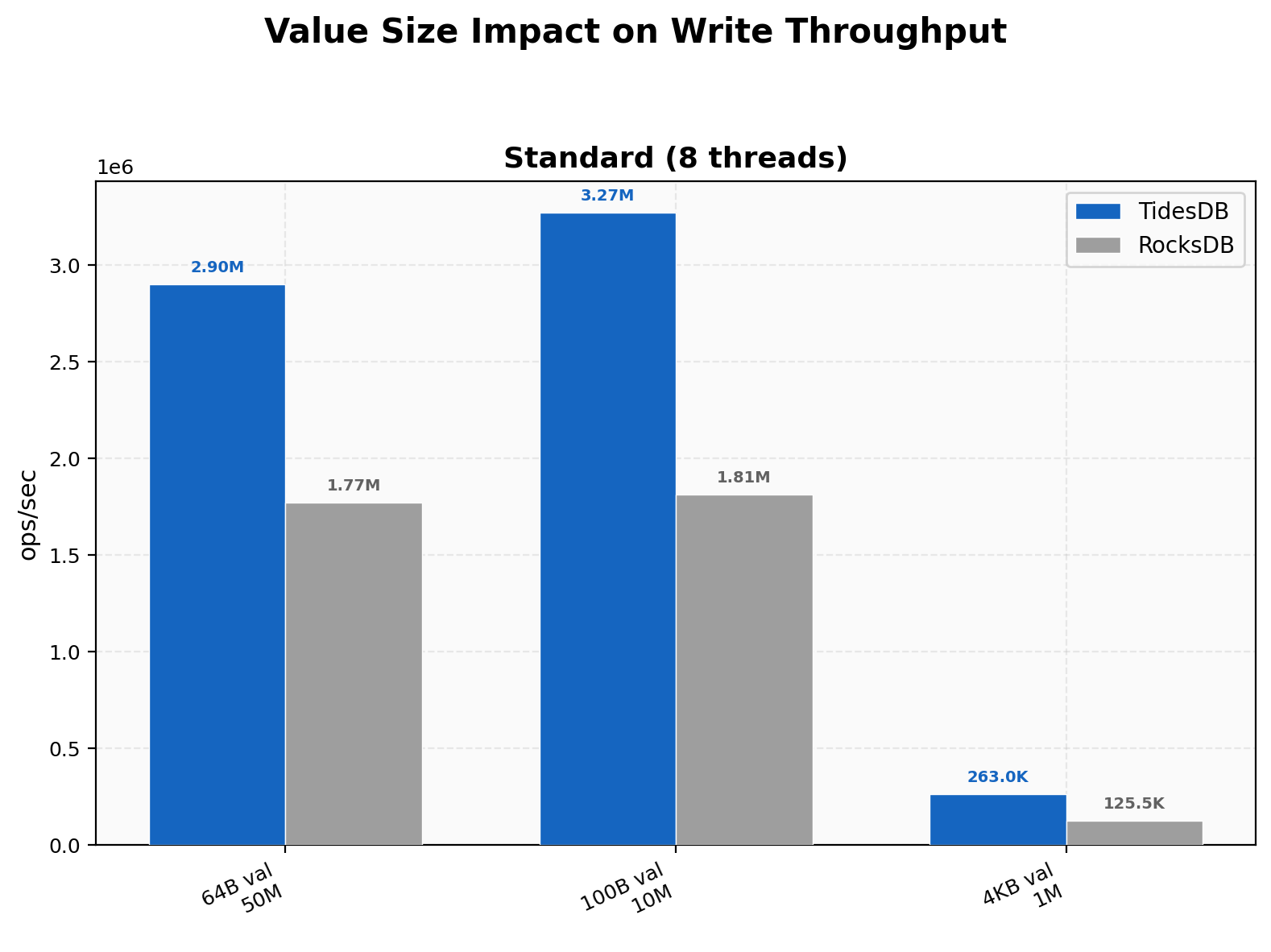
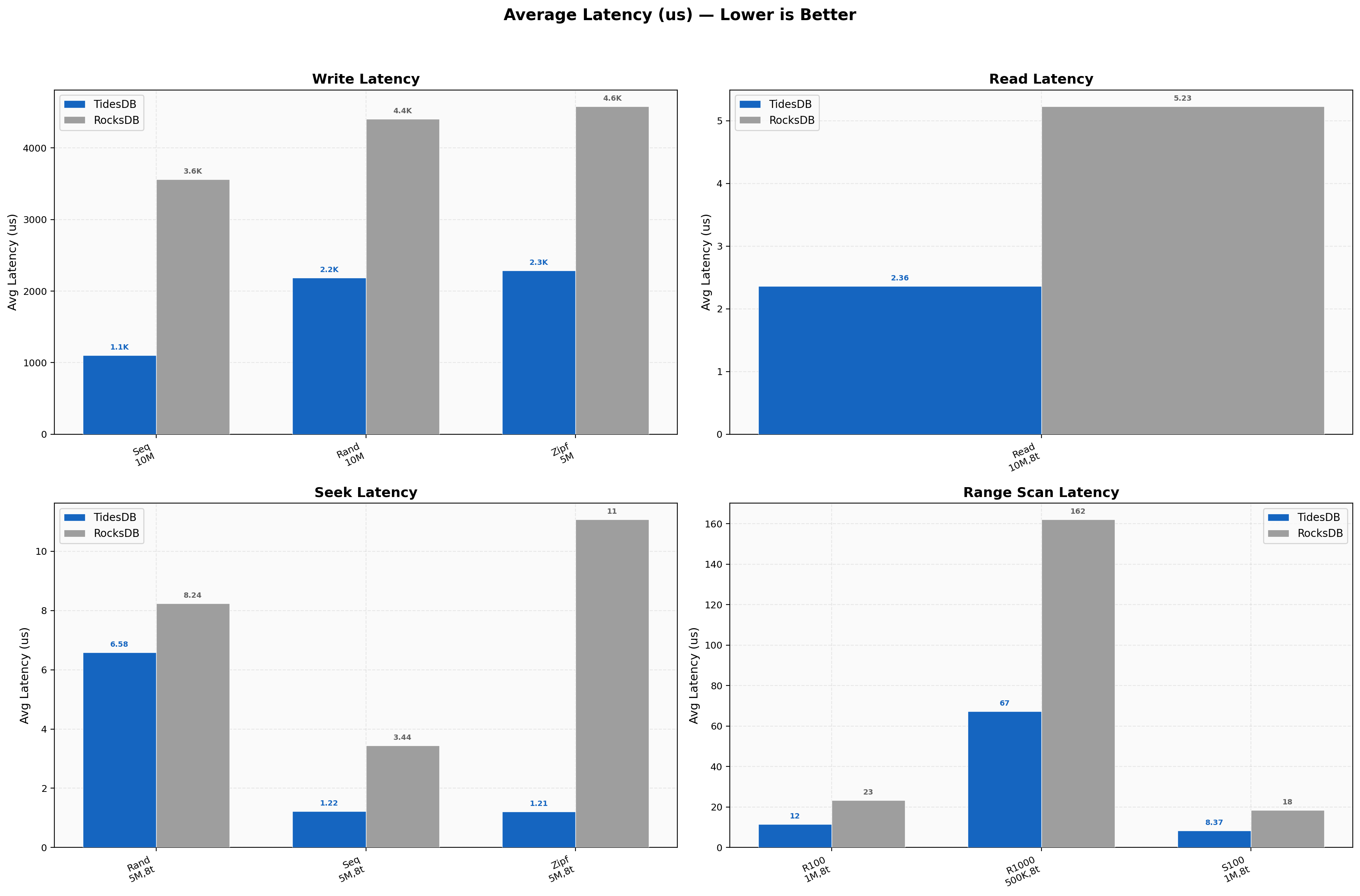
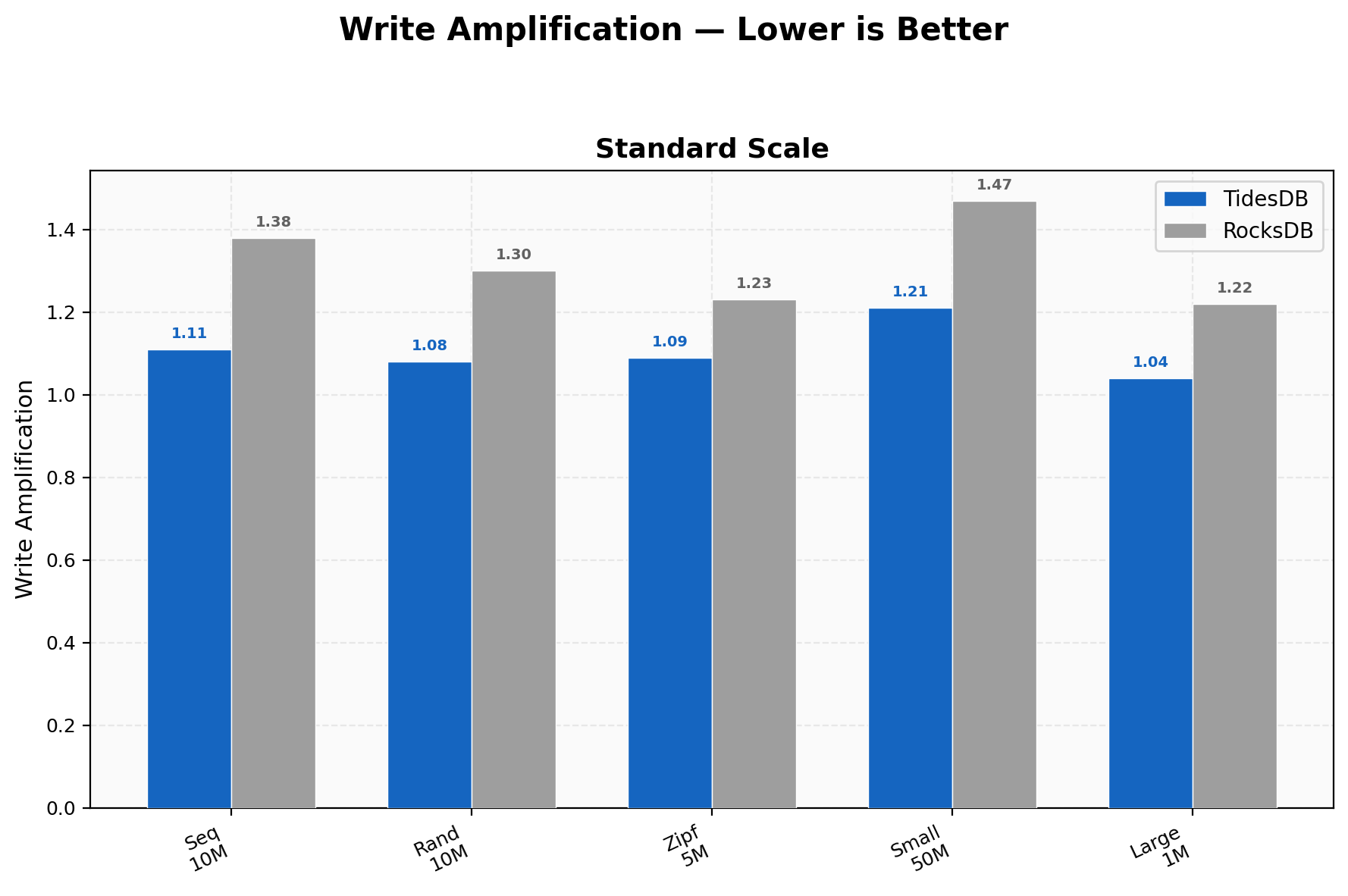
The results on the first environment show TidesDB consistently is faster, provides lower latency, less write amplification, linearly scales, and uses less disk space. This is consistent with past results.
In the second environment, the threadripper I found is actually slower on random reads because the CPU is from 2018. This shows as the clock cache slows down rather dramatically. On the Intel environment it is much faster.
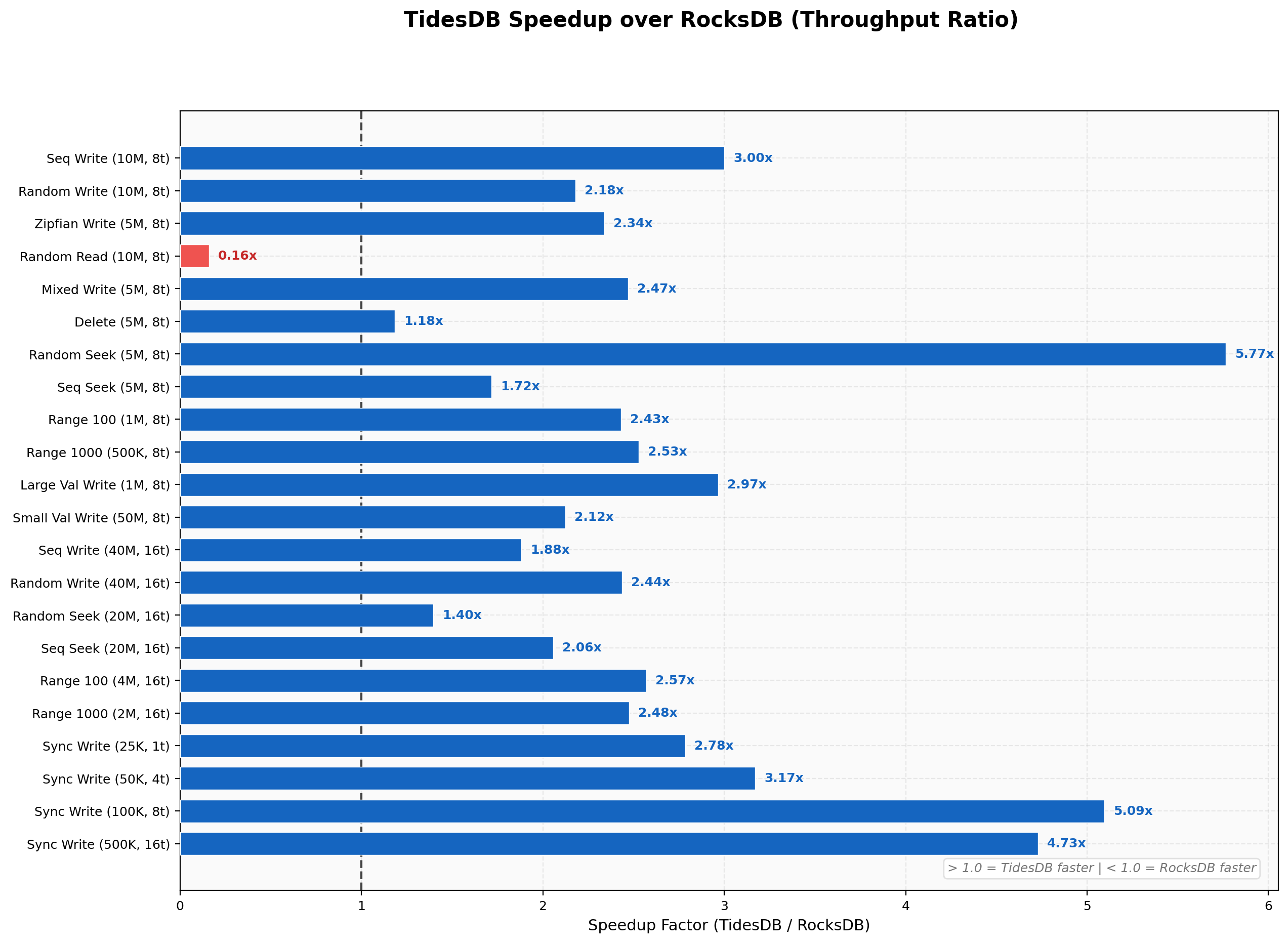
I’ve run it twice and the results are very consistent.
| File Name | Format | SHA256 Checksum |
|---|---|---|
| tidesdb_rocksdb_benchmark_results_20260215_103552.csv | CSV | 60d6e29456afaa1cf4d3ce2d8d92f48408be9f2ce6ab8df220b1fb3c7cb9c498 |
| tidesdb_rocksdb_benchmark_results_20260215_103552.txt | TXT | 9362bfc023d5c1dc1d2b14c3e841a7e3c63a90859f12cd38bf3737ab7ea142ec |
So the latest minor of TidesDB is showing very stable and very consistent across runs though the next upcoming patch will be focusing on the clock cache differences on old CPUs that degrade reads, there is an open issue for it here.
That’s all for today folks.
Thank you for reading!