Benchmark Analysis on TidesDB v7.4.3 & RocksDB v10.9.1

published on January 29th, 2026
In today’s article I’ve benchmarked the latest release of TidesDB v7.4.3 and RocksDB v10.9.1 on write, read, and mixed workloads with the default glibc allocator. I spent time performance testing and finding what could be optimized. In this patch, the focus was mainly on eliminating redundant snapshotting, allocations, and cached time lookups within the skip list by passing the time through from the engine level. The background reaper thread atomically updates the cached time periodically. The cached time is primarily used for TTL, among other things; We want to prevent excessive syscalls in hot paths. I’ve also spent time optimizing the block manager’s handling of cache misses, where I found we could tighten things up and eliminate one pread call per block read. This brought some good results.
I ran the benchmarks twice using tidesdb_rocksdb.sh within the benchtool repo on the specifications described below.
Environment
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
- TidesDB v7.4.3
- RocksDB v10.9.1
Regression from v7.4.2
Before comparing against RocksDB, let’s first look at how v7.4.3 compares to the previous release.
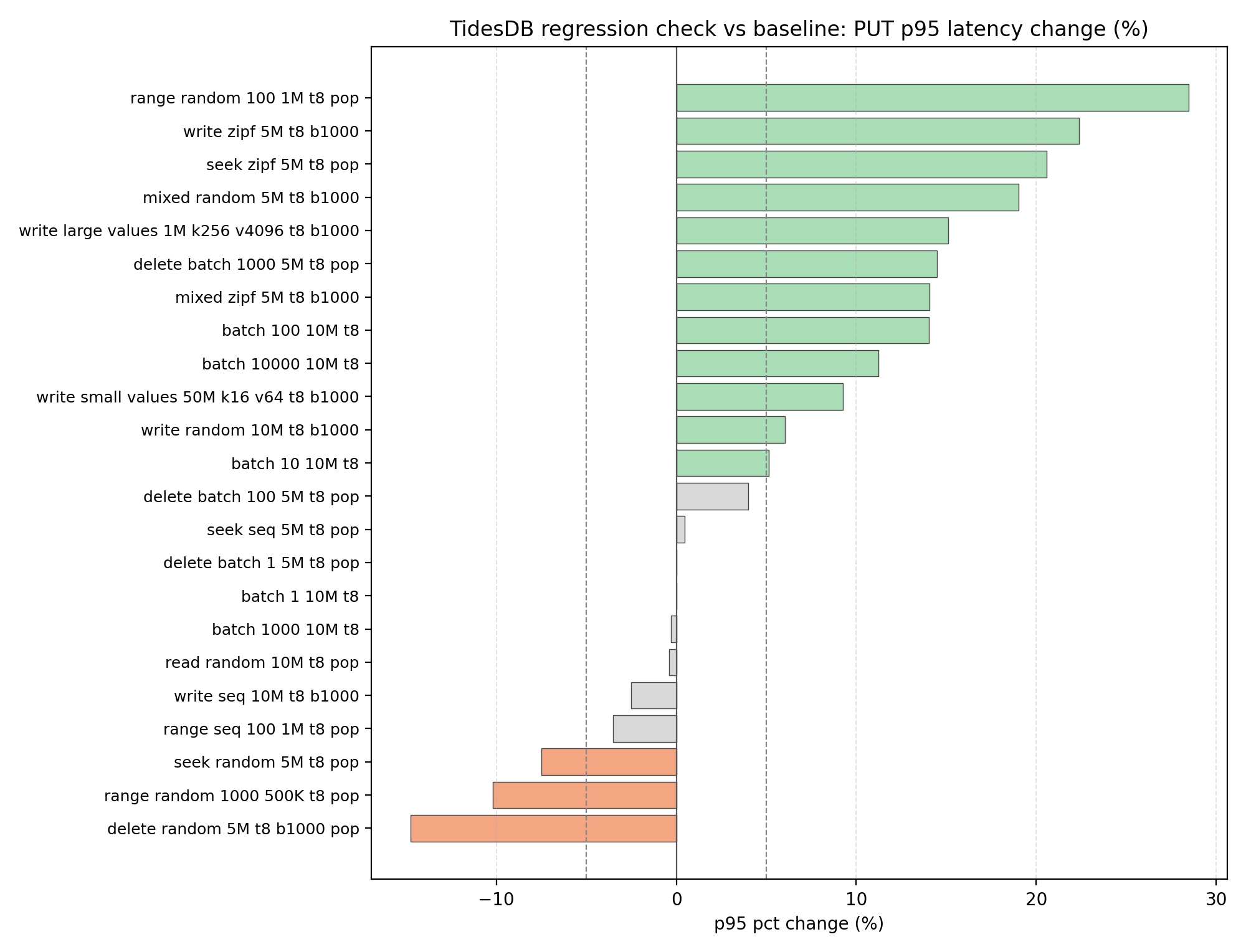
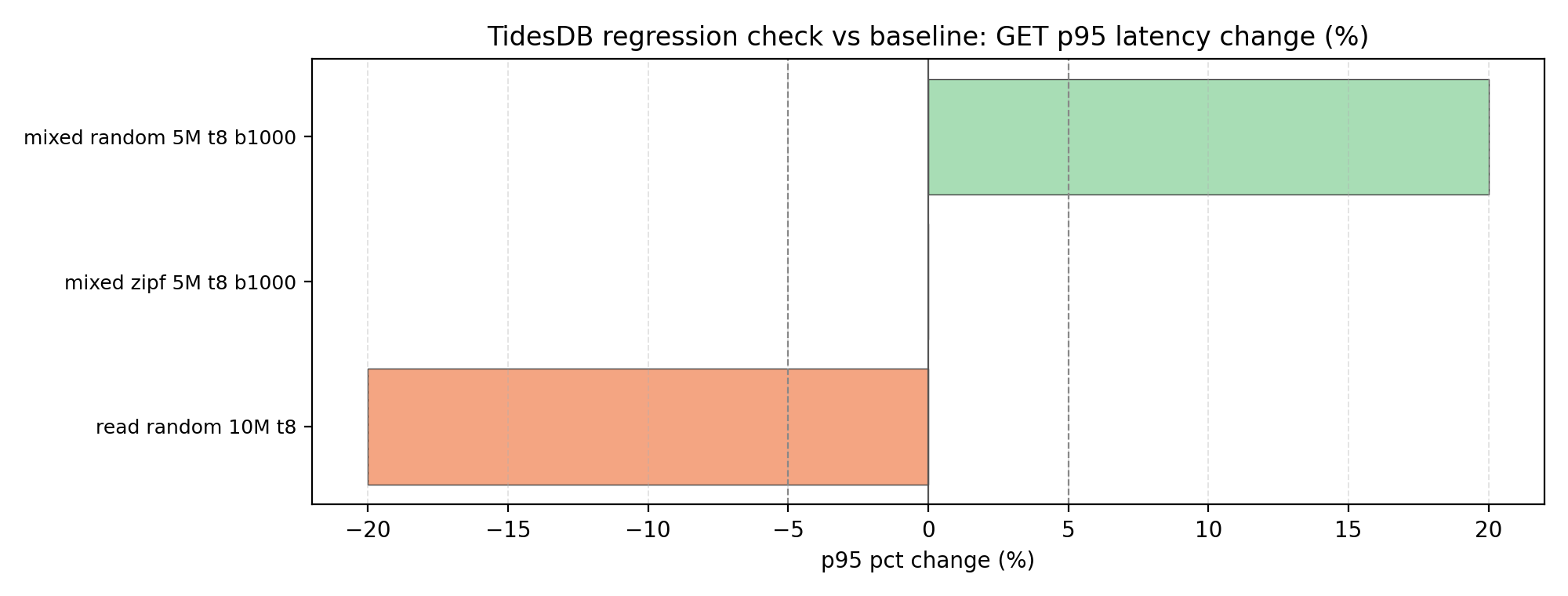
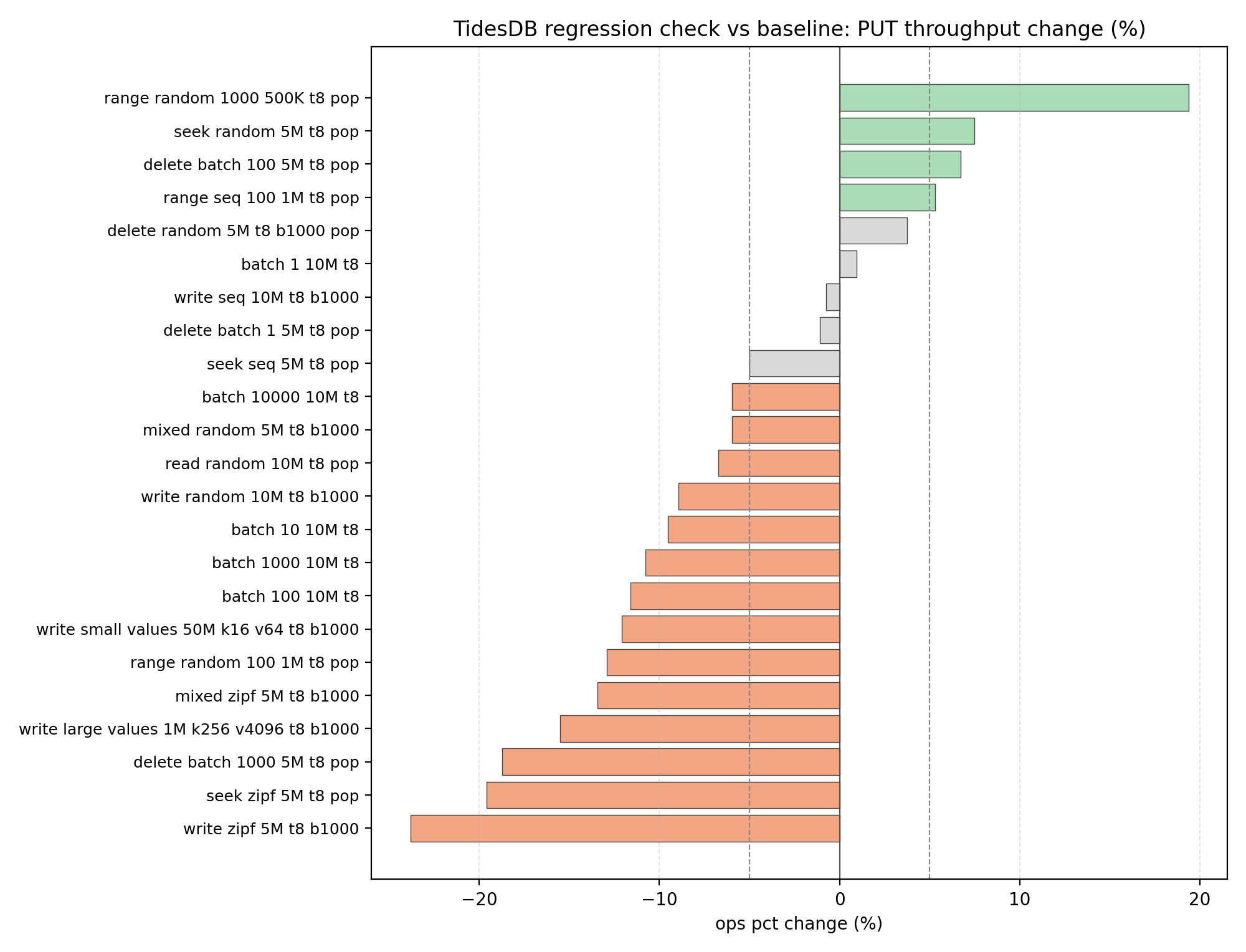
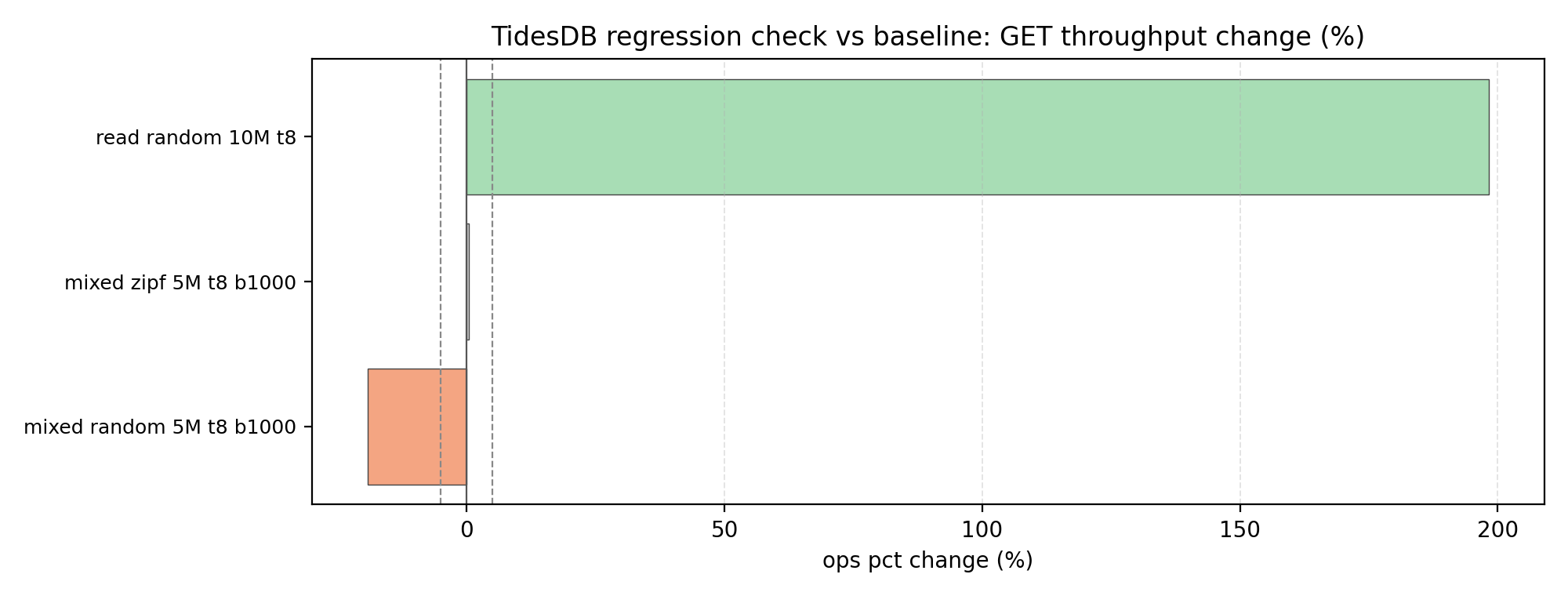
Not too much has changed if you’ve been following, but the key improvement is that read performance has improved by approximately +198% on GET operations, this is the largest win in this patch, no crazy regressions.
TidesDB v7.4.3 vs RocksDB v10.9.1
Now let’s compare TidesDB to the latest version of RocksDB.
PUT throughput (write path)
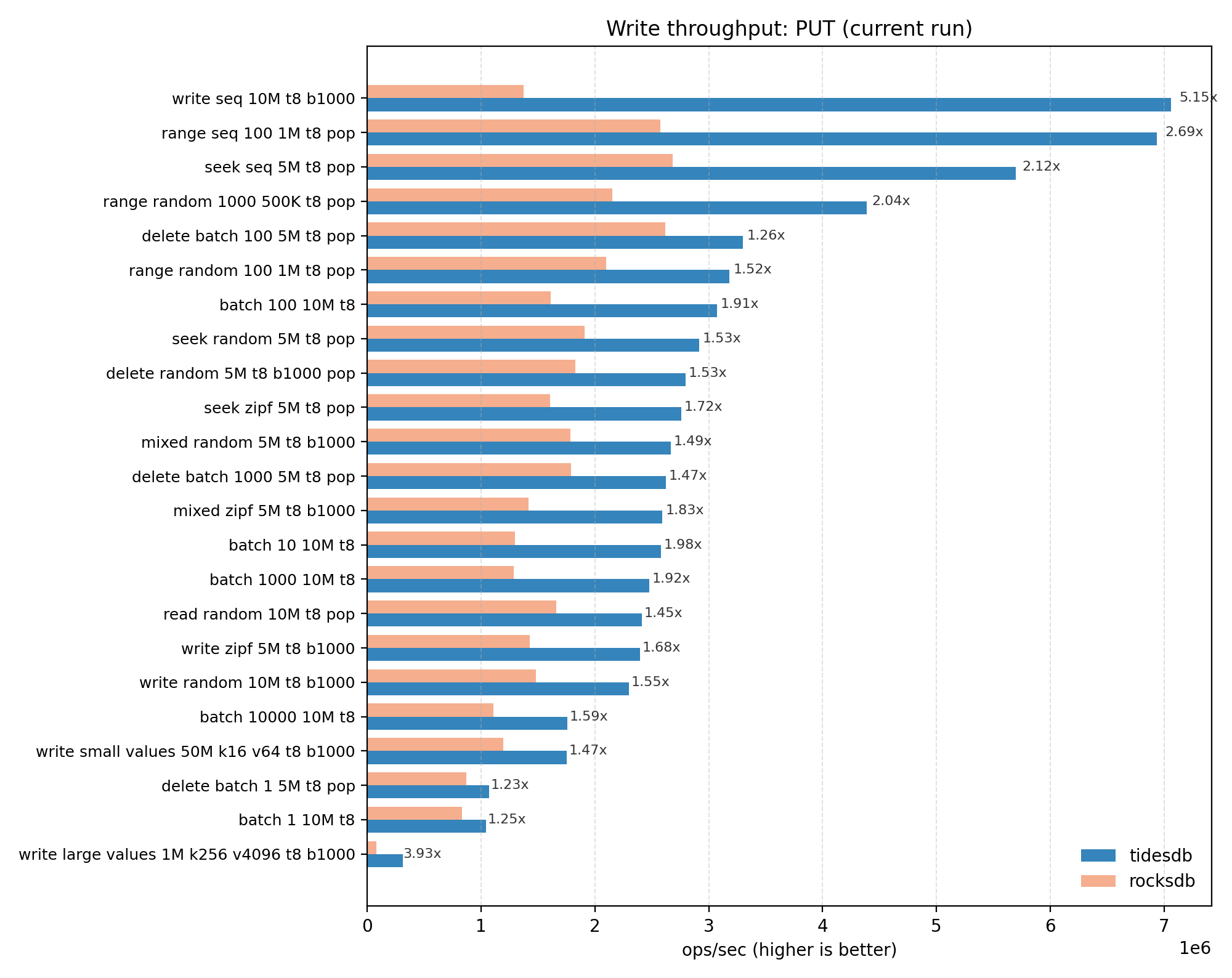
TidesDB is generally ahead on PUT throughput across the tested write/populate workloads with a geomean of ~1.80x and median of ~1.59x (TidesDB/RocksDB). The biggest wins show up on sequential 10M writes and large-value writes; the smallest deltas are around delete-populate and batch-populate style tests.
GET throughput (read path)
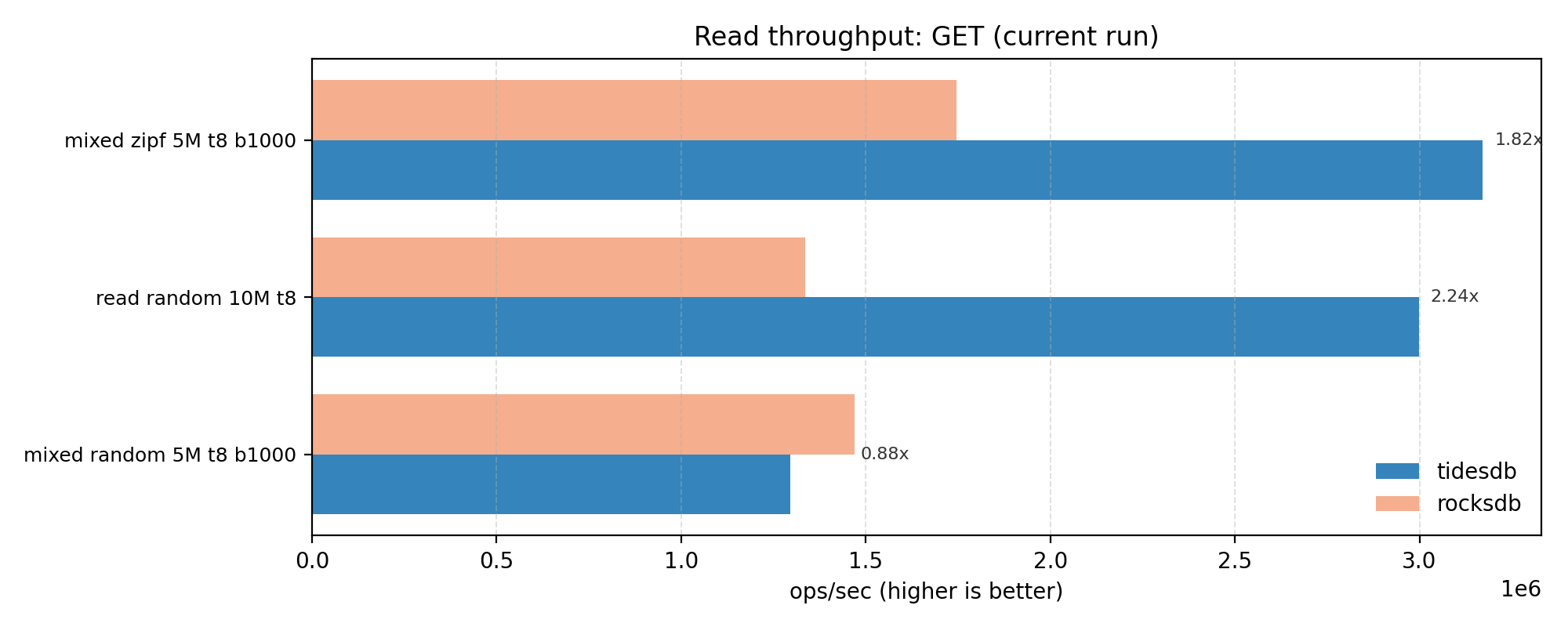
GET performance is mixed but mostly favorable with a geomean of ~1.53x. There is one case where TidesDB is slower in our benchmarks, more notably the mixed workload GET. Though this can be dependant on key patterns, cache state, from what I’ve seen over time.
DELETE throughput
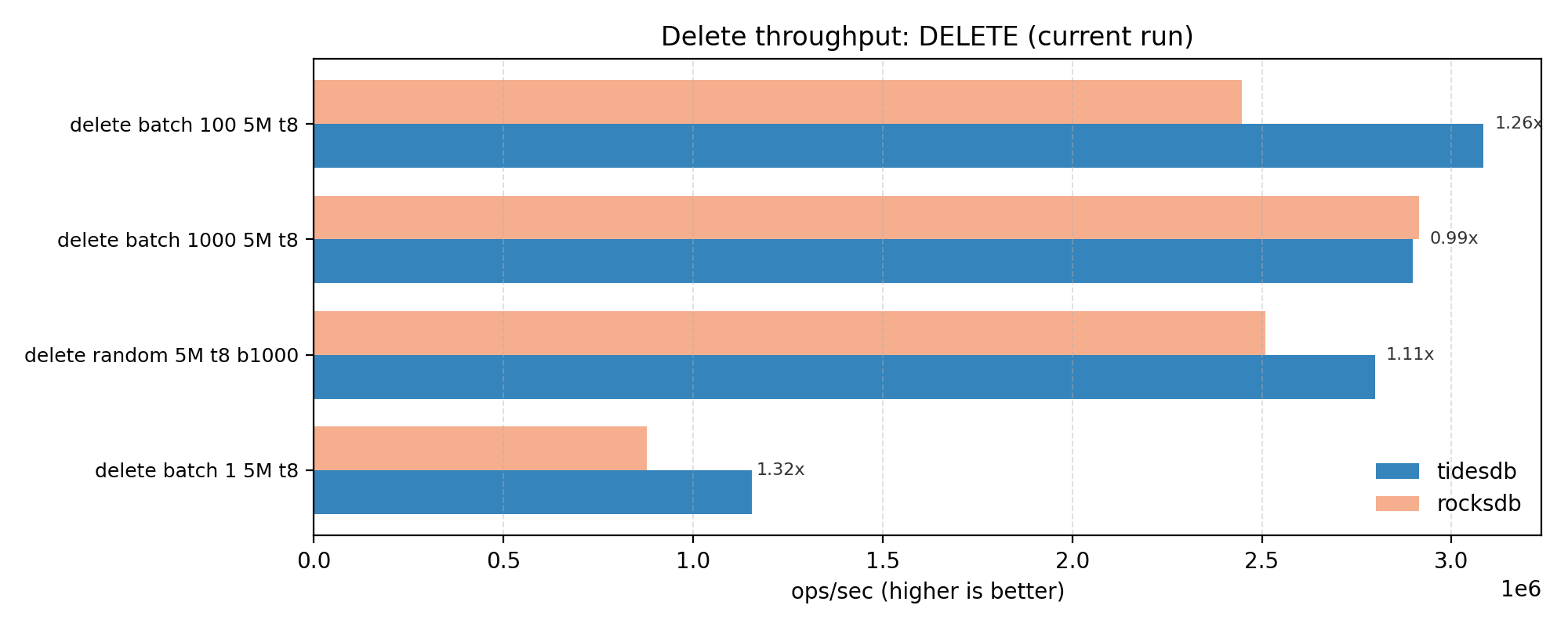
DELETE is close with a geomean of ~1.16x and one case essentially at parity (≈1.0x). This shows us the delete path is not dominated by a single glaring bottleneck for either engine.
SEEK throughput (iteration/point-seek behavior)
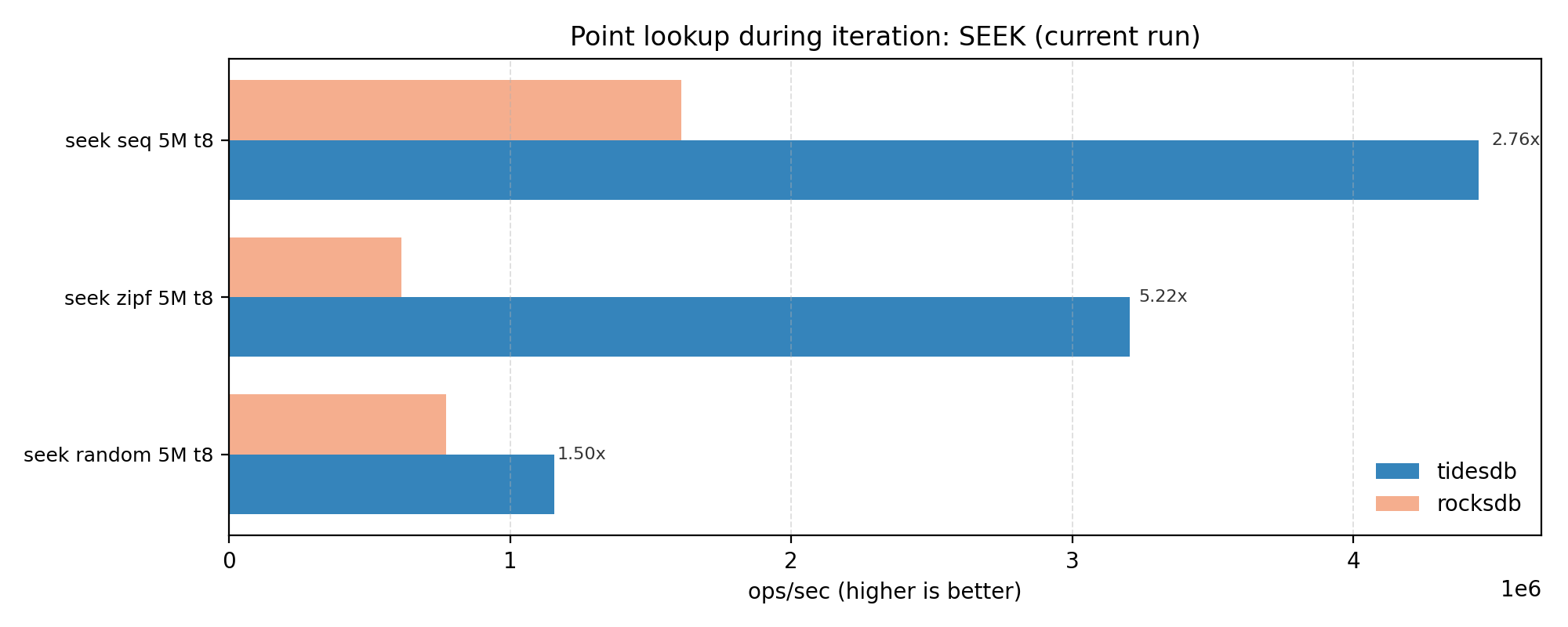
SEEK looks strong for TidesDB with a ~2.79x geomean and a wide spread (roughly 1.5x to 5.2x).
This workload reflects iterator implementation, block format, and index behavior. So it’s nice to see TidesDB perform well here.
RANGE throughput (range scans)
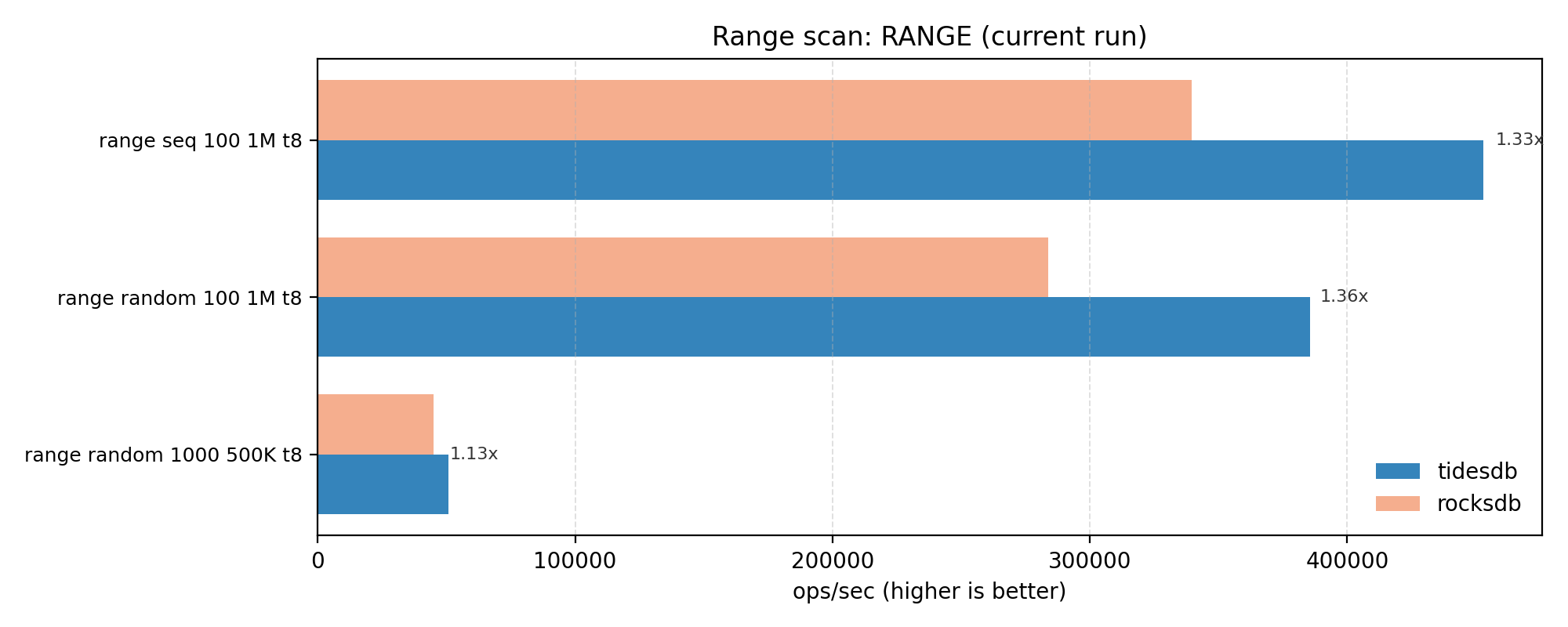
RANGE is a moderate win with a ~1.27x geomean and tighter spread (~1.13x-1.36x). Rather decent.
Tail latency
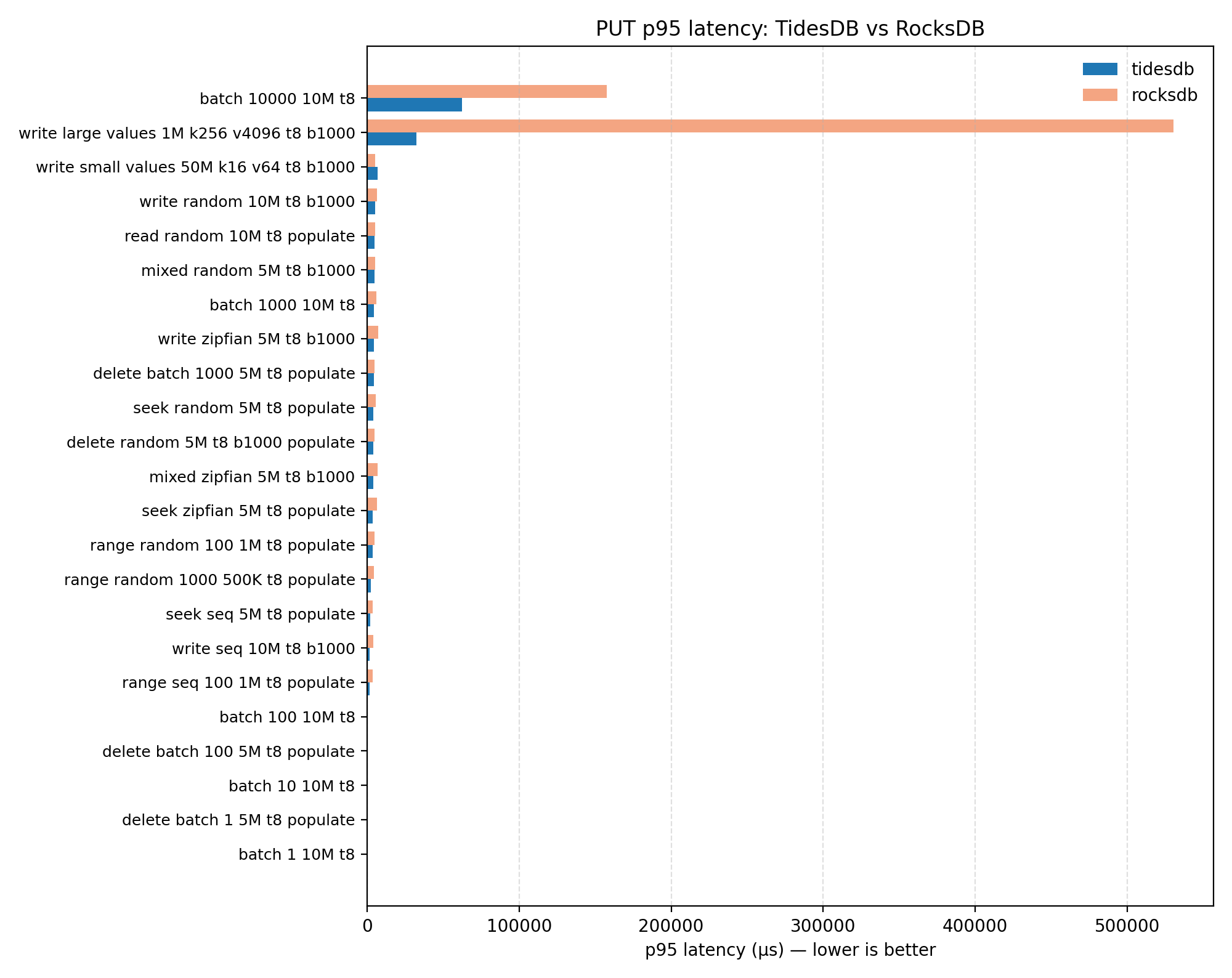
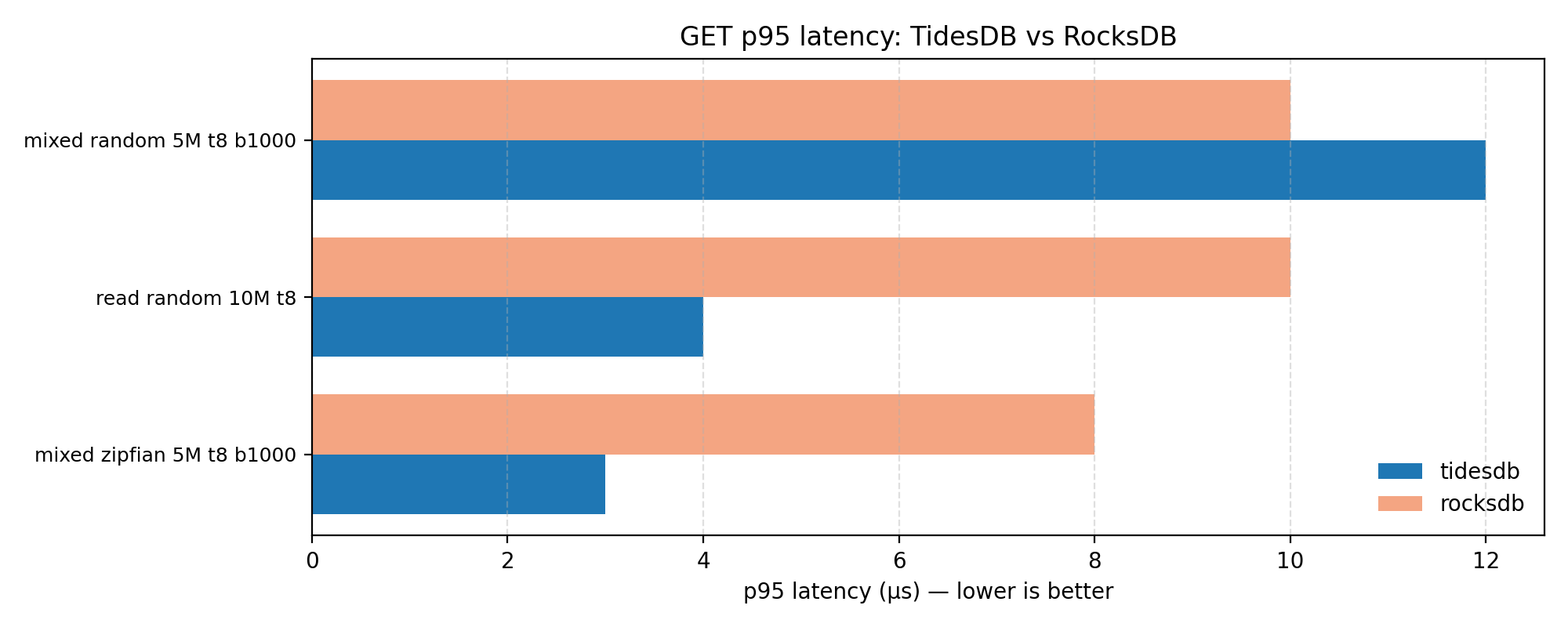
The p95 latency charts above show PUT and GET tail latencies respectively. Points below the diagonal mean TidesDB has lower p95. TidesDB maintains competitive tail latency alongside its throughput gains.
Write amplification and space efficiency
Across the benchmarks, TidesDB consistently showlower write amplification (~1.04-1.21x) compared to RocksDB (~1.22-1.54x). For example, on the write_seq_10M test, TidesDB achieved a write amplification of 1.07 versus RocksDB’s 1.46. On Zipfian workloads, TidesDB’s write amplification was as low as 1.04.
Space amplification - the ratio of actual disk usage to logical data size - also favors TidesDB. TidesDB typically shows space amplification of ~0.02-0.13, while RocksDB ranges from ~0.08-0.22. This translates to smaller on-disk footprints for equivalent datasets, which matters for cost-sensitive deployments.
Final thoughts
Across two independent runs, TidesDB looks to outperform RocksDB on write-heavy, seek-intensive, and range-scan workloads, with gains that exceed observed run-to-run variance. The lower write amplification and space efficiency improvements further strengthen TidesDB’s position for workloads where SSD endurance and storage costs matter.
Both systems exhibit measurable performance variability, particularly under mixed and Zipfian access patterns, underscoring the importance of repeated trials and careful control of database state. No evidence was found of pathological instability in either system.
Thanks for reading!
Want to learn about how TidesDB works? Check out this page.
For raw benchtool data, see below: