Benchmark Analysis on TidesDB v8.2.1 and RocksDB v10.10.1

published on February 6th, 2026
Over the past day I’ve been working at the CPU-instruction level to analyze and optimize TidesDB’s read path, which led to both correctness and performance improvements across several core components. The patch fixes issues like expired (time-to-live) memtable entries falling through to SSTable lookups, broken format strings, and silently ignored allocation and I/O errors, while also tightening hot paths in the skiplist and block manager by removing dead prefetches, redundant checks, and unnecessary syscalls.
I reworked the block cache to eliminate global atomic contention using per-partition counters, significantly improving multithreaded scaling, and accelerated B+ tree reads via arena-based deserialization and bulk deallocation to reduce allocator overhead. Collectively, these changes reduce per-SSTable read-miss cost by hundreds of nanoseconds and translate into measurable throughput gains on read-heavy, scan-heavy, and cold-cache workloads, alongside cleaner and more maintainable internals.
Environment
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
- TidesDB v8.2.1
- RocksDB v10.10.1 (Pinned L0 index/filter blocks, HyperClock cache, block indexes)
- GCC (glibc)
- LZ4 Compression used for both engines
The tool used for this analysis is the TidesDB benchtool project, which can be found here. The script used for this analysis was tidesdb_rocksdb.sh. In one run I used --btree option for TidesDB so one run uses a B+tree KLog format and the first run uses regular highly compressed Block KLog format.
PUT throughput across workloads
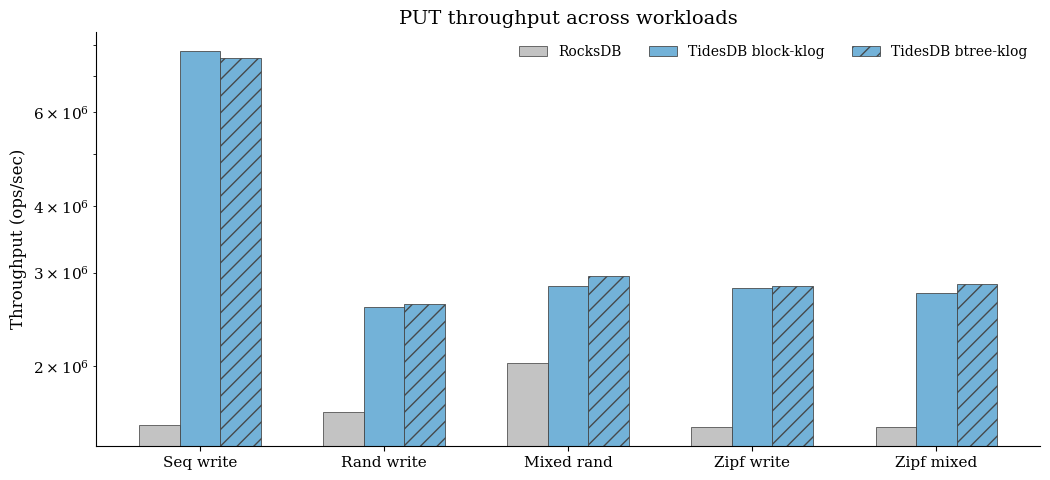 With a single RocksDB baseline per workload, both TidesDB formats are consistently faster on writes. The largest gain is sequential ingest - block-klog ~5.04x and btree-klog ~4.88x vs RocksDB (≈7.80M / 7.56M vs ≈1.55M ops/s baseline). Random and mixed writes remain strong ~1.57-1.59x on random write and ~1.40-1.46x on mixed random. Zipfian workloads also show robust advantages ~1.82-1.84x on Zipf write and ~1.79-1.86x on Zipf mixed.
With a single RocksDB baseline per workload, both TidesDB formats are consistently faster on writes. The largest gain is sequential ingest - block-klog ~5.04x and btree-klog ~4.88x vs RocksDB (≈7.80M / 7.56M vs ≈1.55M ops/s baseline). Random and mixed writes remain strong ~1.57-1.59x on random write and ~1.40-1.46x on mixed random. Zipfian workloads also show robust advantages ~1.82-1.84x on Zipf write and ~1.79-1.86x on Zipf mixed.
GET throughput across workloads
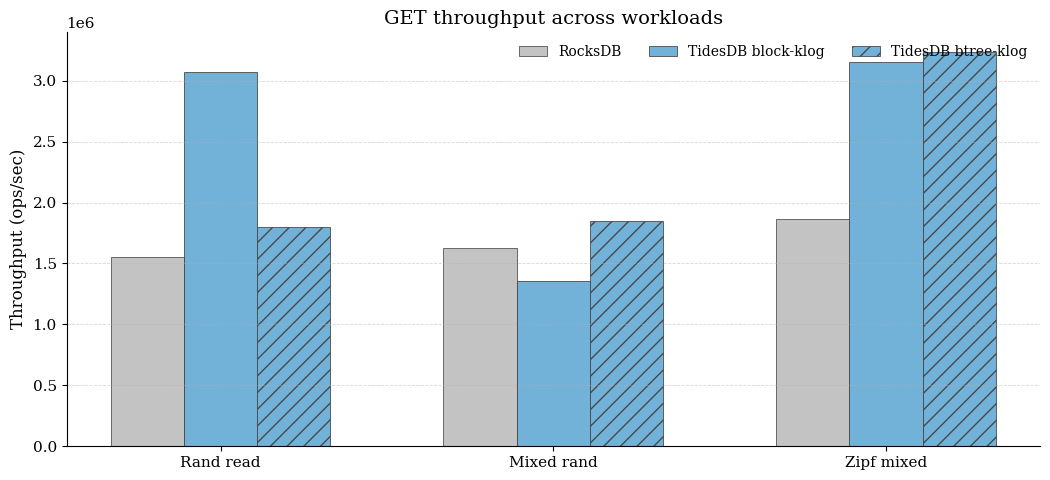
Reads are format - and workload-sensitive against the collapsed RocksDB baseline. On pure random read, block-klog is ~1.98x faster (≈3.07M vs ≈1.55M ops/s), while btree-klog is ~1.16x (≈1.80M vs ≈1.55M). On mixed random, block-klog is below baseline (~0.83x), but btree-klog becomes above baseline (~1.1x). On Zipf mixed, both formats are clearly ahead block-klog ~1.69x and btree-klog ~1.73x vs RocksDB baseline (≈3.15-3.23M vs ≈1.86M ops/s).
PUT p99 tail latency across workloads
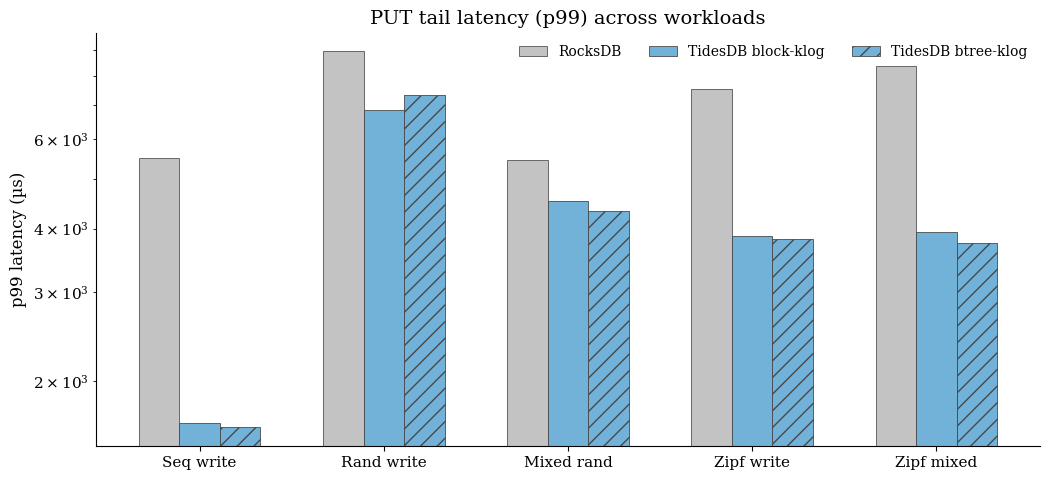 Using the collapsed RocksDB baseline (and noting the two-run range), TidesDB generally improves tail latency on write-heavy workloads, especially sequential and Zipfian cases. For sequential write, TidesDB p99 is ≈1.55-1.62 ms versus RocksDB’s ≈5-6 ms range across the two baseline runs, indicating materially better tail behavior alongside the throughput advantage. Random write tail latency is closer block-klog is lower than RocksDB, while btree-klog is competitive but can be higher depending on workload shape - so the key point is that the major tail-latency win is most pronounced in seq/Zipf patterns, not uniformly in every random-heavy case.
Using the collapsed RocksDB baseline (and noting the two-run range), TidesDB generally improves tail latency on write-heavy workloads, especially sequential and Zipfian cases. For sequential write, TidesDB p99 is ≈1.55-1.62 ms versus RocksDB’s ≈5-6 ms range across the two baseline runs, indicating materially better tail behavior alongside the throughput advantage. Random write tail latency is closer block-klog is lower than RocksDB, while btree-klog is competitive but can be higher depending on workload shape - so the key point is that the major tail-latency win is most pronounced in seq/Zipf patterns, not uniformly in every random-heavy case.
On-disk database size after workload
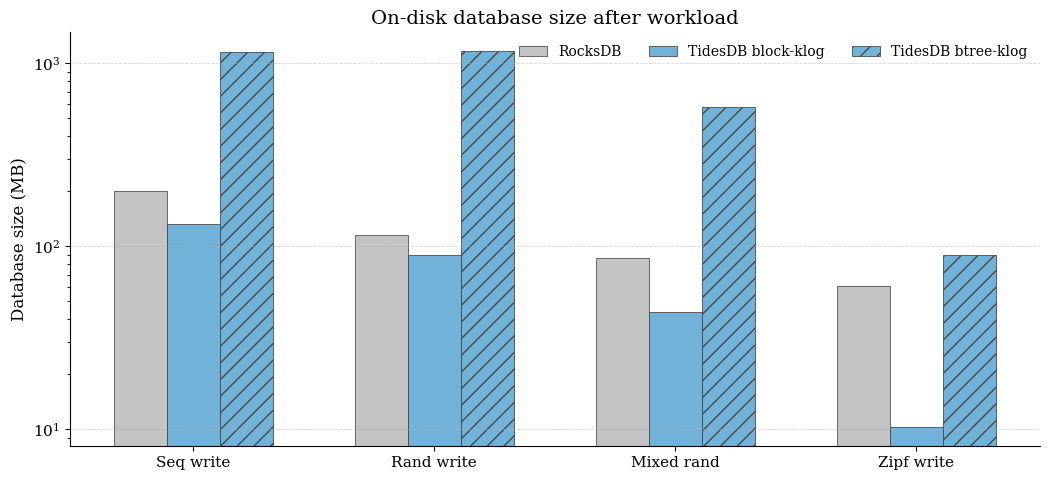 The default KLog block format is consistently smaller than RocksDB, while btree-klog is dramatically larger on uniform-key workloads.
The default KLog block format is consistently smaller than RocksDB, while btree-klog is dramatically larger on uniform-key workloads.
For example, on seq write, RocksDB baseline is ≈200.9 MB, block-klog ≈132.8 MB, but btree-klog ≈1156 MB. Similar behavior appears on random and mixed random writes (RocksDB ≈115.9/86.2 MB vs block-klog ≈90.0/43.7 MB, while btree-klog is ≈1164/580 MB). Under Zipf write, btree-klog shrinks (≈90.1 MB) but still trails block-klog (≈10.2 MB) and remains larger than the RocksDB baseline (≈60.4 MB).
Space amplification factor (lower is better)
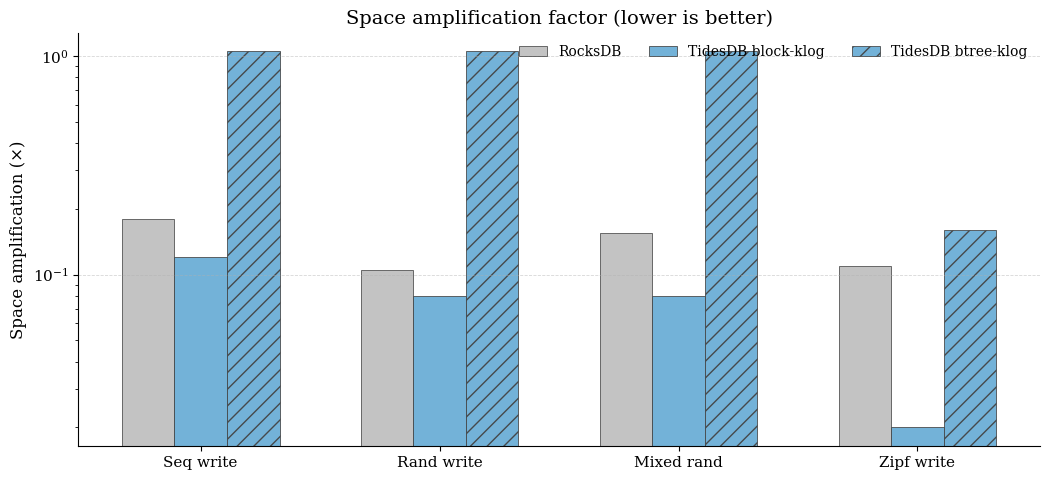 Against the single RocksDB baseline, block-klog is consistently the most space-efficient, while btree-klog incurs high space amplification on uniform workloads. On seq/random/mixed-rand writes, RocksDB baseline is roughly ~0.105-0.18x, block-klog improves further to ~0.08-0.12x, but btree-klog is about ~1.05× (roughly an order of magnitude higher than RocksDB in these cases). On Zipf write, all engines improve, but the ordering remains - RocksDB baseline ≈0.11x, block-klog ≈0.02x, btree-klog ≈0.16x.
Against the single RocksDB baseline, block-klog is consistently the most space-efficient, while btree-klog incurs high space amplification on uniform workloads. On seq/random/mixed-rand writes, RocksDB baseline is roughly ~0.105-0.18x, block-klog improves further to ~0.08-0.12x, but btree-klog is about ~1.05× (roughly an order of magnitude higher than RocksDB in these cases). On Zipf write, all engines improve, but the ordering remains - RocksDB baseline ≈0.11x, block-klog ≈0.02x, btree-klog ≈0.16x.
So the results are rather interesting as you can see, if your priority is space efficiency and strong read performance on pure random reads with some more memory usage, block-klog is the clear winner (tiny DB sizes + very low space amp + top GET throughput on random read). Though if your priority is mixed-workload GET throughput (and you can tolerate much larger footprint on uniform workloads) the btree klog format can be attractive, especially where “mixed random” GET matters.
Against RocksDB both formats show big write wins (especially sequential ingest with 8 threads hitting both engines in every benchmark), but the formats trade read shape vs space very differently.
Thanks for reading!
—
Raw CSV-TXT benchtool data: