Plugging into MariaDB

published on February 5th, 2026
I can’t help but tinker and get curious when building. It just happens naturally. As some of you may know, or maybe all of you. I’ve been working on a pluggable engine for MariaDB, the project goes under the name TideSQL. It’s an engine that just plugs into MariaDB using TidesDB.
Now you may think “Why would I want to do that?” Well, I truly wanted to bring the power of TidesDB to MariaDB, I thought it would be an interesting fit, seals do live in the tides.
MariaDB has incredible documentation on how to approach building such a pluggable engine. I found it to be a great resource for learning, as well as looking at the other pluggable engines that MariaDB has. These pluggable engines are MyRocks, and MyISAM, InnoDB being the default engine.
With that said, TidesDB’s column family architecture maps 1:1 to MariaDB tables. Each column family is an independent namespace with its own memtable, WAL, levels, compression, klog formats, bloom filters, etc. The plugin simply creates a column family per table and separate CFs for each secondary index, fulltext index, and spatial index, etc. There’s no impedance mismatch. MariaDB says “create table”, TidesDB creates a column family.
TidesDB’s Transaction Model Matches MariaDB’s Handlerton Interface
TidesDB natively provides:
- Begin/commit/rollback - maps directly to handlerton::commit / handlerton::rollback
- Snapshot isolation - maps to start_consistent_snapshot
- Multi-CF atomic commits via shared global sequence - maps to multi-table transactions
- 5 isolation levels - MariaDB’s SET TRANSACTION ISOLATION LEVEL maps directly to TidesDB’s isolation enum
- XA prepare/recover/commit_by_xid - TidesDB transactional support maps directly to the XA handlerton callbacks
The plugin doesn’t need to build transaction semantics on top of a non-transactional store. TidesDB already speaks the same transactional language MariaDB pretty much expects.
TidesDB exposes a clean C API (tidesdb_txn_begin, tidesdb_txn_put, tidesdb_txn_get, tidesdb_txn_commit, tidesdb_iter_*, etc.) that maps naturally to handler method calls, for example:
| MariaDB handler call | TidesDB C API |
|---|---|
write_row() | tidesdb_txn_put() |
rnd_next() | tidesdb_iter_next() + tidesdb_iter_key/value() |
index_read_map() | tidesdb_iter_seek() on index CF |
delete_row() | tidesdb_txn_delete() |
truncate() | tidesdb_drop_column_family() + tidesdb_create_column_family() |
optimize() | tidesdb_compact() |
The plugin is essentially a translation layer that converts MariaDB’s row-oriented SQL interface into TidesDB’s key-value operations. The heavy lifting (MVCC, compaction, crash recovery, compression, bloom filters, clock caching, lock-free concurrency, etc) all lives in the TidesDB library itself.
The plugin currently implements a rather full handler interface:
- ACID transactions with MVCC, XA distributed transactions, savepoints
- Primary, secondary, composite, clustered indexes
- Foreign keys with CASCADE, SET NULL, and self-referencing support
- Fulltext search via inverted indexes, spatial indexes via Z-order encoding
- Online DDL with three tiers (instant metadata, inplace indexes, copy for columns)
- Index Condition Pushdown, Multi-Range Read, condition pushdown, rowid filter pushdown
- TTL per-row expiration, encryption via MariaDB’s plugin API
- Partitioning, virtual/generated columns, bulk insert optimization
- Persistent statistics, tablespace import/export, online backup and more…
Benchmarks
I ran sysbench against TidesDB v1.2.0 and InnoDB on the same MariaDB 12.1.2 instance (10K rows, 60s per test, 10s warmup). Here’s what the numbers look like.
Environment:
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
- TidesDB v8.2.0
- GCC (glibc)
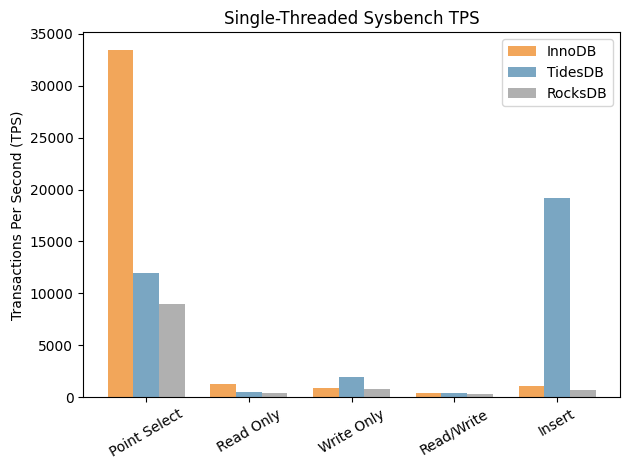
Single-threaded (1 thread):
Multi-threaded (4 threads):
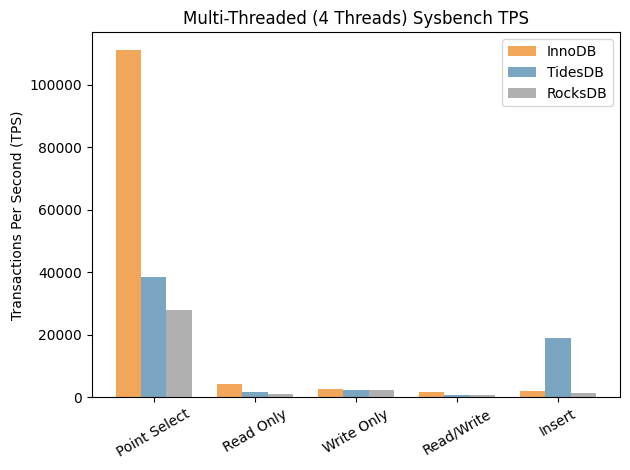
The write numbers speak for themselves. TidesDB is 9-18x faster on pure inserts and over 2x faster on write-only workloads. TidesDB’s p99 on inserts is 0.12ms vs InnoDB’s 4.65ms, with InnoDB occasionally spiking to 373ms.
To put these numbers in context, Mark Callaghan’s extensive MyRocks vs InnoDB benchmarks tell an interesting story. Looking at the actual data for MyRocks 8.0.32, MyRocks loses to InnoDB on most write workloads, write-only at 0.89x, inserts at 0.74x, deletes at 0.74x, non-index updates at 0.70x, read-write mixed at 0.65x. The only write benchmark where MyRocks seems to win is update-index at 1.80x, thanks to read-free secondary index maintenance I believe. TideSQL is pulling ahead of InnoDB on writes by 2.2x (write-only) and 9-18x (inserts).
On reads, InnoDB is faster, of course, roughly 2.5x on read-only (20,700 vs 8,100 QPS) and 3x on point selects. But TidesDB’s read numbers are pretty solid in absolute terms - 8,100 QPS on read-only transactions and 11,900 QPS on point selects is real throughput.
From Callaghan’s data, MyRocks 8.0.32 gets 0.75-0.77x of InnoDB on point queries before fragmentation, dropping to 0.53-0.75x after range workloads fragment the tree. Range queries land at 0.46-0.65x, and read-only transactions at 0.63-0.71x.
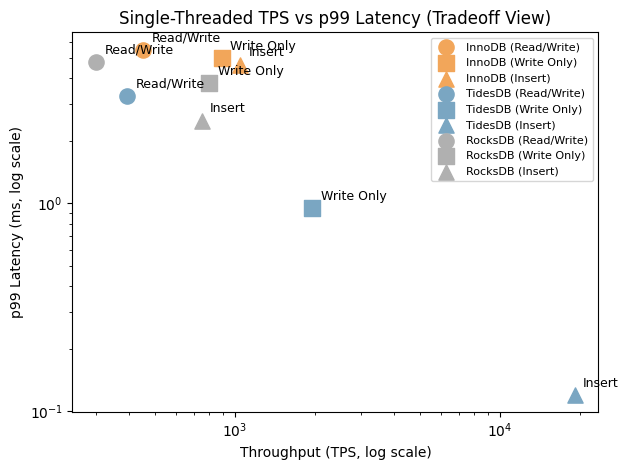
What really stands out is the consistency, and this is where TidesDB shines on the read/write mixed workload. Yes, InnoDB’s average TPS is higher. But the 10-second interval data - TidesDB holds steady at 8,200-8,320 QPS every single interval with p99 latency locked in between 3.0-3.3ms.
InnoDB swings between 10,154 and 12,014 QPS - an 18% variance - with p99 bouncing from 2.1ms to 5.5ms. TidesDB’s throughput variance is under 2%. InnoDB’s worst p99 (5.5ms) is 1.8x worse than TidesDB’s worst (3.3ms).
On write-only, the same pattern but even more dramatic! TidesDB is rock steady at 11,500-11,900 QPS (p99=0.95ms) while InnoDB swings between 4,671 and 5,989 QPS (p99=2.5-5.0ms).
At 4 threads, InnoDB pulls ahead on read/write mixed (0.47x) partly due to MVCC conflict retries in my observations.
A Note on LSMB+ (B+Tree KLog Layout)
TidesDB supports two SSTable (KLog) formats - the B+tree layout and a simpler block layout. The B+tree format organizes keys within each KLog as a B+tree with prefix compression, key indirection tables, and delta encoding - giving O(log N) point lookups within a single SSTable instead of binary search over block indexes which are also expensive to keep in memory. In TideSQL the B+Tree KLog format is the default, in TidesDB the library column family defaults to block layout.
I ran the same sysbench suite with tidesdb_use_btree=OFF (block layout) and the results were nearly identical at this scale - within a few percent either way. The difference would show up with larger KLogs across many levels, where each SSTable may contain millions of keys and the B+tree’s O(log N) in-file lookup avoids scanning through many block index entries. The tradeoff is that the B+tree KLog layout takes more space on disk due to the internal node overhead.
What’s Next
There’s plenty of room to optimize TideSQL regarding reads, reduce MVCC conflict rates under concurrency and further benchmark larger workloads.
Thanks for reading!
—
- TidesSQL Source: github.com/tidesdb/tidesql
- TidesSQL Write up: tidesql.md
- Sysbench data (zip): sysbench.zip