TidesDB 8 with optional LSM-B+Tree KLog Indexes

published on February 1st, 2026
So over the past year let’s say I’ve experimented a lot. I mean a lot. I experimented with a btree layer in the past in a project I was working on called WildcatDB. Over time writing TidesDB, I’ve thought about ways we can add an optional klog persisted index that would utilize a B+Tree structure to improve read performance. Though obviously an LSM-tree has many levels and files, this can greatly improve read performance, as we will soon see below. I’ve been working on this for a bit on and off but decided to spend time and get it right and implemented for TidesDB 8. With that in this article we will be going over the performance differences, you can read more about the B+tree implemented in the design doc if ya want.
Environment
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
- TidesDB v8.0.0
- GCC (glibc)
With that let’s get into the nitty gritty.
PUT throughput (write path)
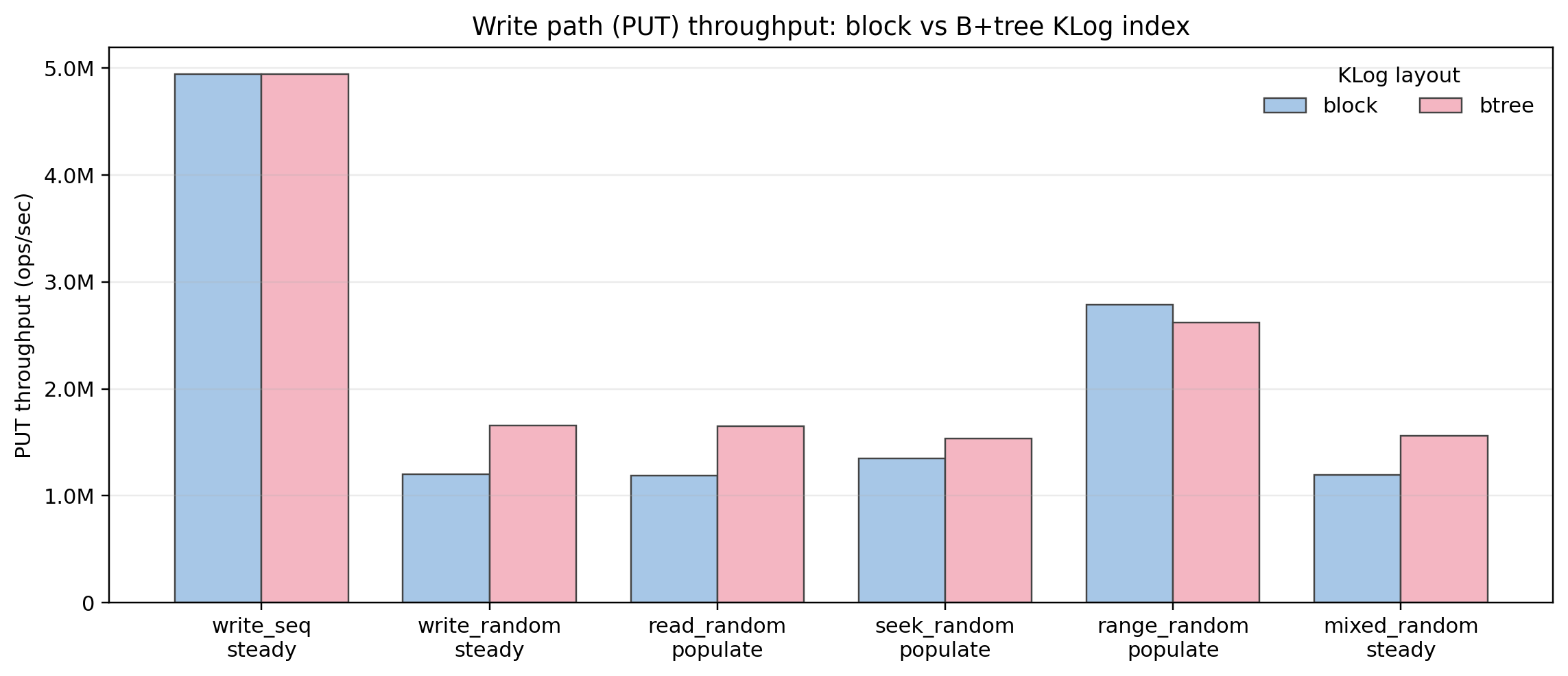
This plot shows that moving KLogs to a B+tree does not penalize the sequential write path, write_seq steady is essentially identical between block and B+tree.
Steady-state GET / SEEK / RANGE throughput
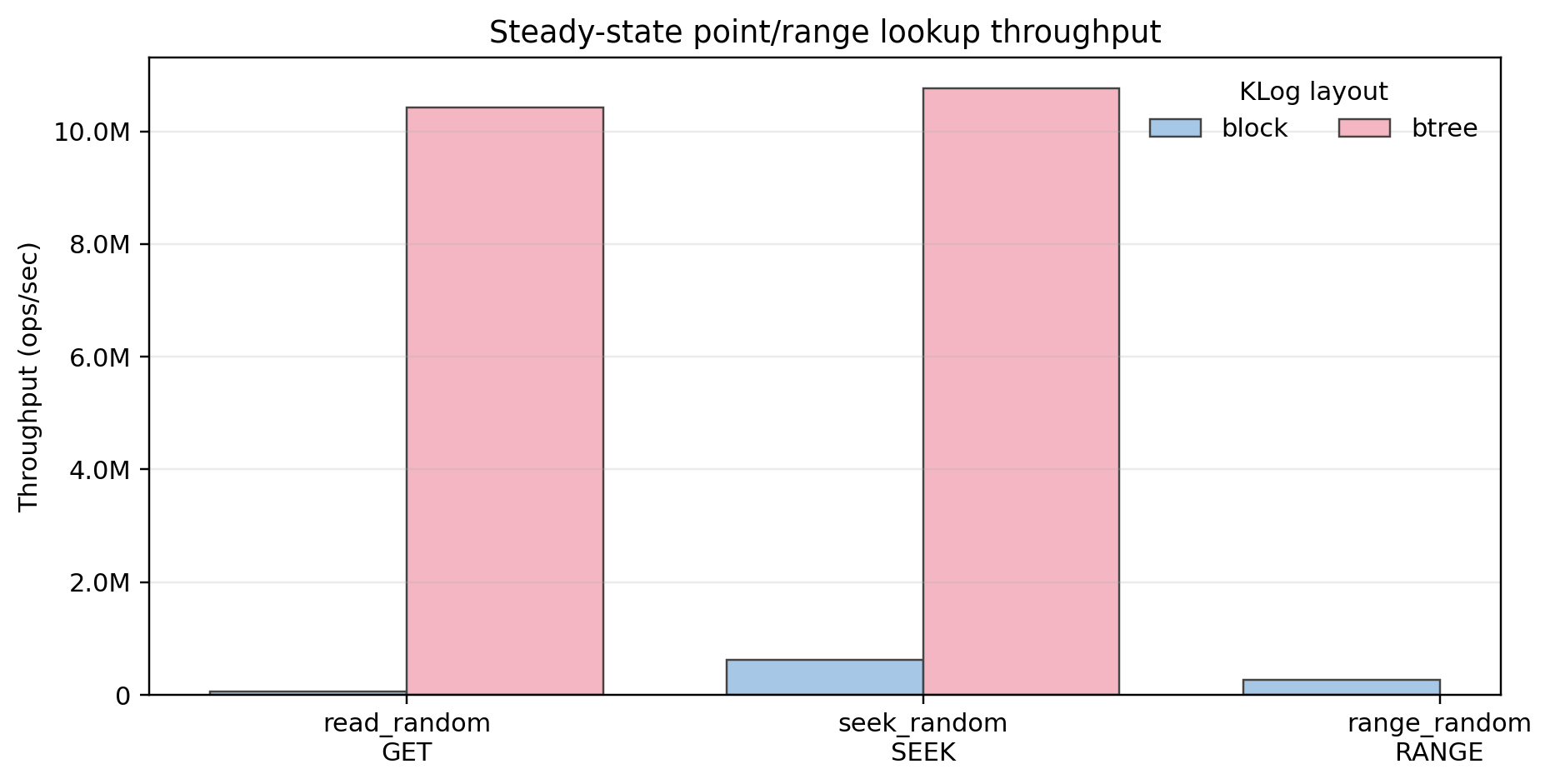
This figure captures the core architectural win. For point lookups and seeks, the B+tree-backed KLog is orders of magnitude faster than the block layout ~160x for GET and ~17x for SEEK. The B+tree changes the performance class of reads.
PUT tail latency (p95 with p99 markers)
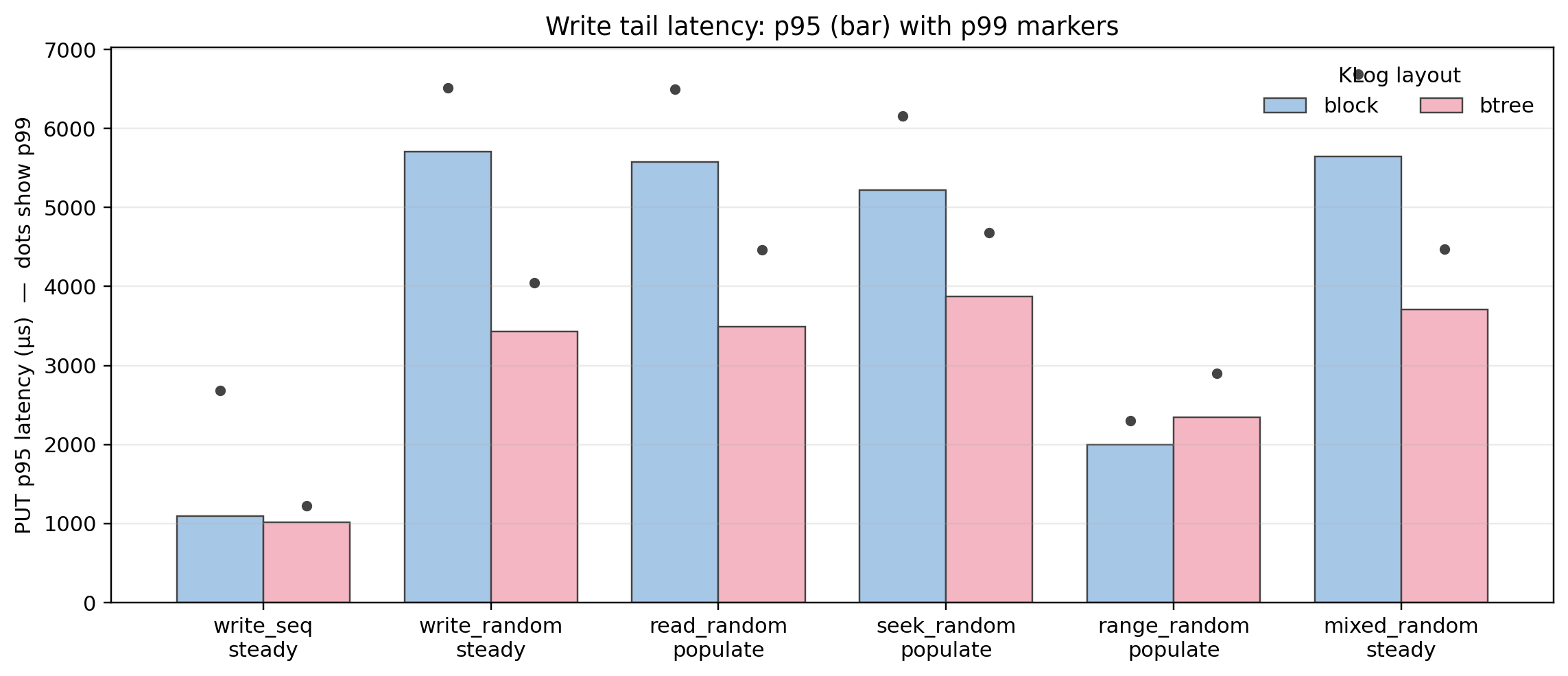
In random, mixed, and populate phases, p95 latency drops by roughly 30-40%, and p99 follows the same trend. The exception is range-populate, where B+tree p95 is worse, consistent with its lower PUT throughput there, but not too concerning.
Read / seek / range tail latency (log scale)
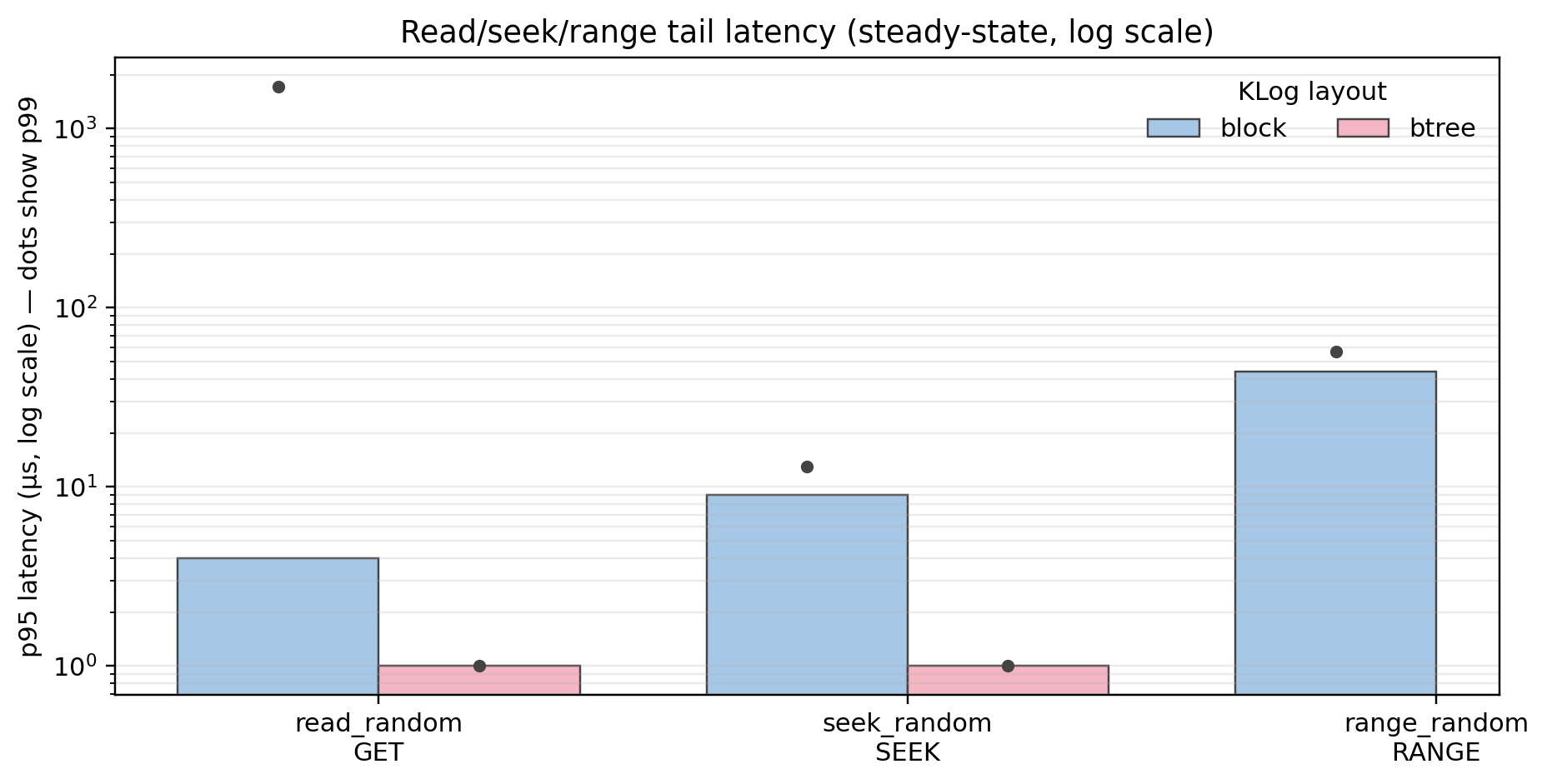
On a log scale, this plot highlights how the B+tree collapses read-side tail latency. For GET and SEEK, B+tree p95 sits around ~1µs while the block layout shows rare but occasional p99 outliers (hundreds to thousands of microseconds). This pattern indicates cache misses or slow-path traversal in the block design that the B+tree avoids. The mixed workload shows a small regression for B+tree at p95.
On-disk database size
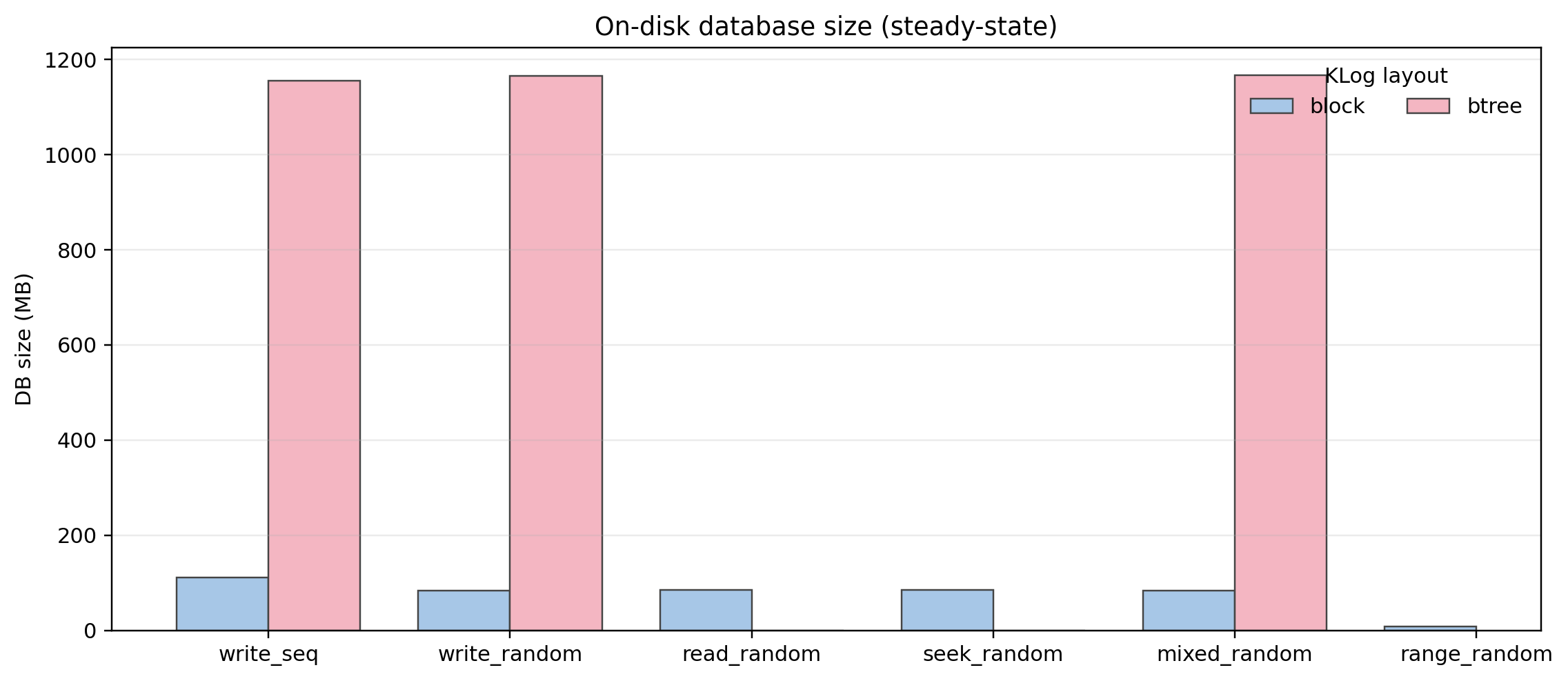
The B+tree variant consumes an order of magnitude more disk space than the block layout in several workloads (~1.1-1.2GB vs ~100MB). This makes sense, as the block layout is highly optimized for space efficiency.
Peak RSS
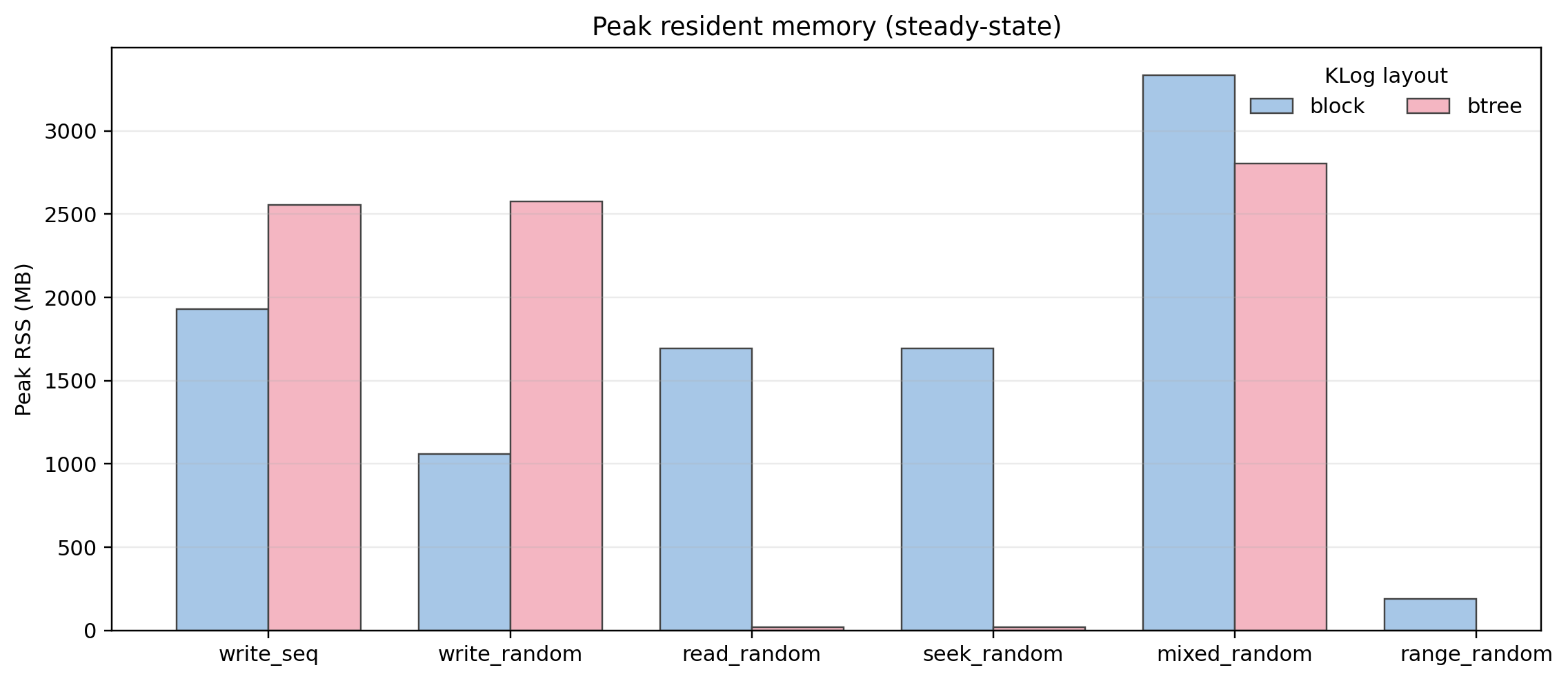
Peak RSS shows mixed behavior. Mostly due to immutable memtable flushes and reference counting for TidesDB’s lock-free architecture but overall stable.
Second run
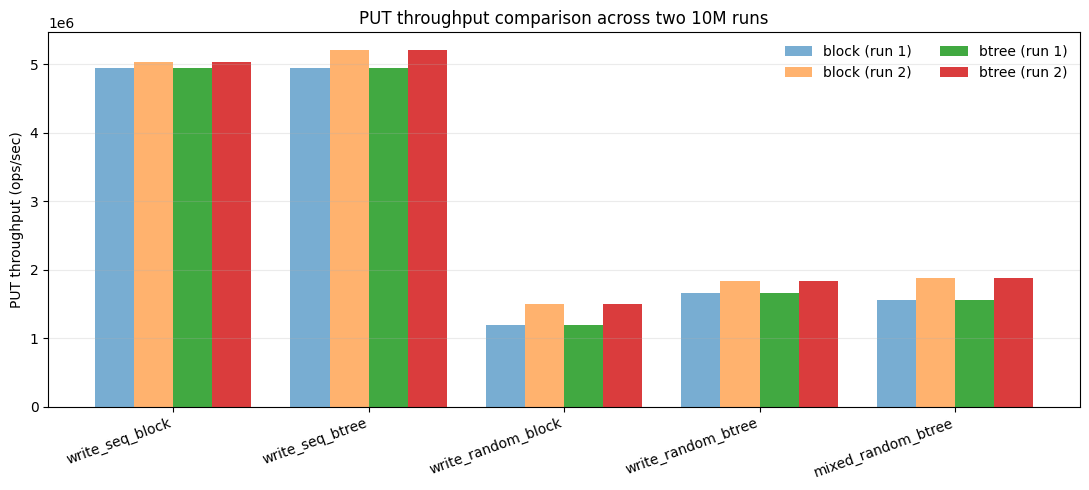
Across both 10M runs, PUT throughput is stable and repeatable, with the same ordering every time. Sequential writes remain effectively tied between block and B+tree, confirming that indexing the KLog does not harm the append path.
Conclusion
The B+tree-backed KLog preserves sequential write performance, improves random and mixed operation throughput, and does so reproducibly across executions. Combined with the previously observed order-of-magnitude gains in read and seek performance and improved write tail latency, these results indicate that indexing the KLog with a B+tree changes the performance envelope of TidesDB without introducing instability or regressions in the common case.
Thanks for reading!
—
Thank you to @KevBurnsJr on reddit for his review and feedback on this article!
For raw data:
For benchtool runner used:
TidesDB 8: