TPC-C Benchmark Analysis on TidesDB v9.0.2 in TideSQL v4.2.0 in MariaDB v11.8.6

published on April 2nd, 2026
The latest patch of TidesDB brings a few performance improvements thus I thought a new benchmark analysis article was warranted.
The specs for the environment are
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
- GCC (glibc)
Though you can build TidesDB with jemalloc, tcmalloc, etc. I use the default allocator for this benchmark.
I will say, when running TidesDB in MariaDB it’s a good idea to use a better allocator. mimalloc and tcmalloc have shown to really optimize the library for concurrent workloads and reduce memory fragmentation which can in turn lead to better performance.
Same hardware and OS as the previous benchmark. Same my.cnf. This is the small-cache configuration from that article, 64MB buffer/cache for both InnoDB and TidesDB.
The difference is the engine library version, TidesDB v9.0.2 via PR #583, a patch release containing library-level optimizations over v9.0.0.
I am running MariaDB v11.8.6 and HammerDB 5.0 TPROC-C.
I use a specific shell script to run the benchmark, which you can find here (7c5df694eddf6759c1818a47fbd0ad9f3f2697ec3d8c689c1ca054be3dbcdea4).
./run_tpcc_mariadb.sh -b tpcc --warehouses 40 --tpcc-vu 8 --tpcc-build-vu 8 --rampup 1 --duration 2 --settle 5 -H ~/HammerDB-5.0 -e tidesdb -u hammerdb --pass hammerdb123 -S /tmp/mariadb.socktidesdb is replaced for any engine, innodb, rocksdb, etc.
What changed in v9.0.2
- Incremental block advance where iterator
next()now parses only the next entry from raw bytes via block index offsets instead of fully deserializing the block. This removed an O(n) deserialization that was ~40% of CPU in seek-heavy workloads. - Block cache lookup on sequential iteration where
merge_source_advancenow checks the block cache before issuingpread, enabling cached range scans. - Inline integer comparators where 4/8-byte keys use byte-swapped integer comparison; 16/32-byte comparators use chunked 8-byte loads with early exit instead of
memcmp. - Queue snapshot where replaced O(n²)
queue_peek_atloops with a single O(n) snapshot under one lock. - Seq-only SSTable read, where we skip min-max and bloom filter checks when max sequence number is less than the requested sequence number.
Additional fixes included CLOCK cache NUMA re-probing for migrated threads and correcting memory pressure accounting in unified memtable mode.
The perf profile flattened. Top function dropped from 6.47% (_int_malloc) to 4.69% (klog_block_deserialize). kernel pread fell from 3.81% to 1.40%. XXH32 disappeared entirely (cache hits now bypass checksum). bloom_filter_add and build_indexed_block_data no longer appear in the top functions.
Results
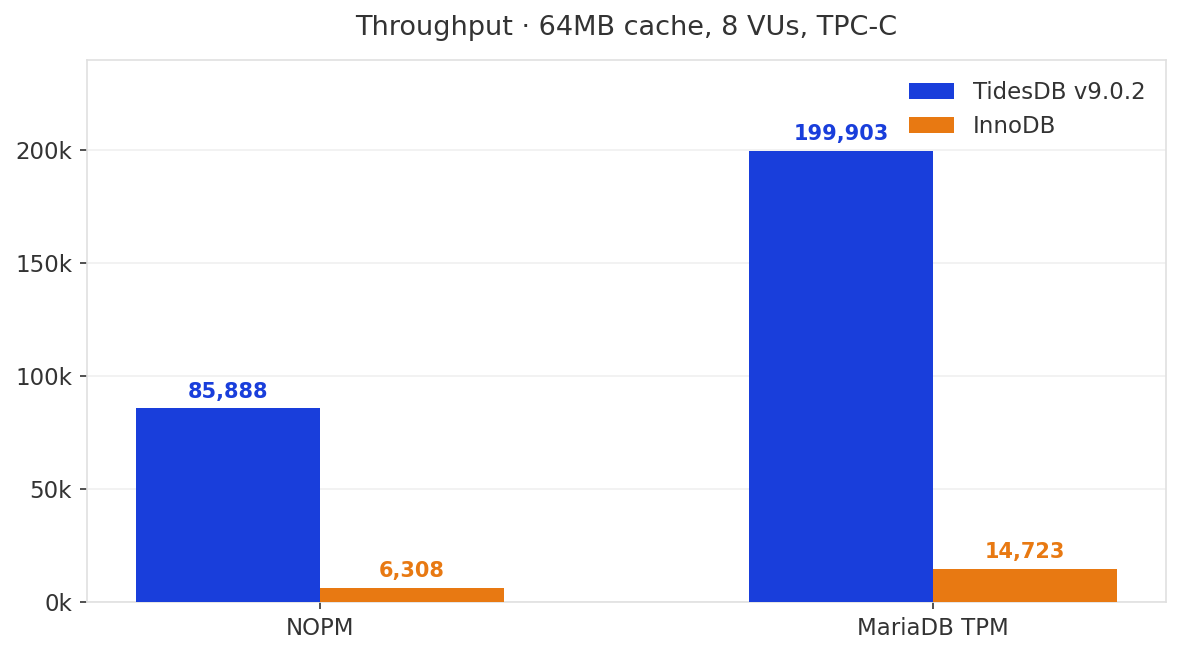
Across two runs TidesDB v9.0.2 posted 81,959 and 85,888 NOPM. The peak run is shown below.
| Metric | TidesDB v9.0.2 | InnoDB | Ratio |
|---|---|---|---|
| NOPM | 85,888 | 6,308 | 13.6x |
| MariaDB TPM | 199,903 | 14,723 | 13.6x |
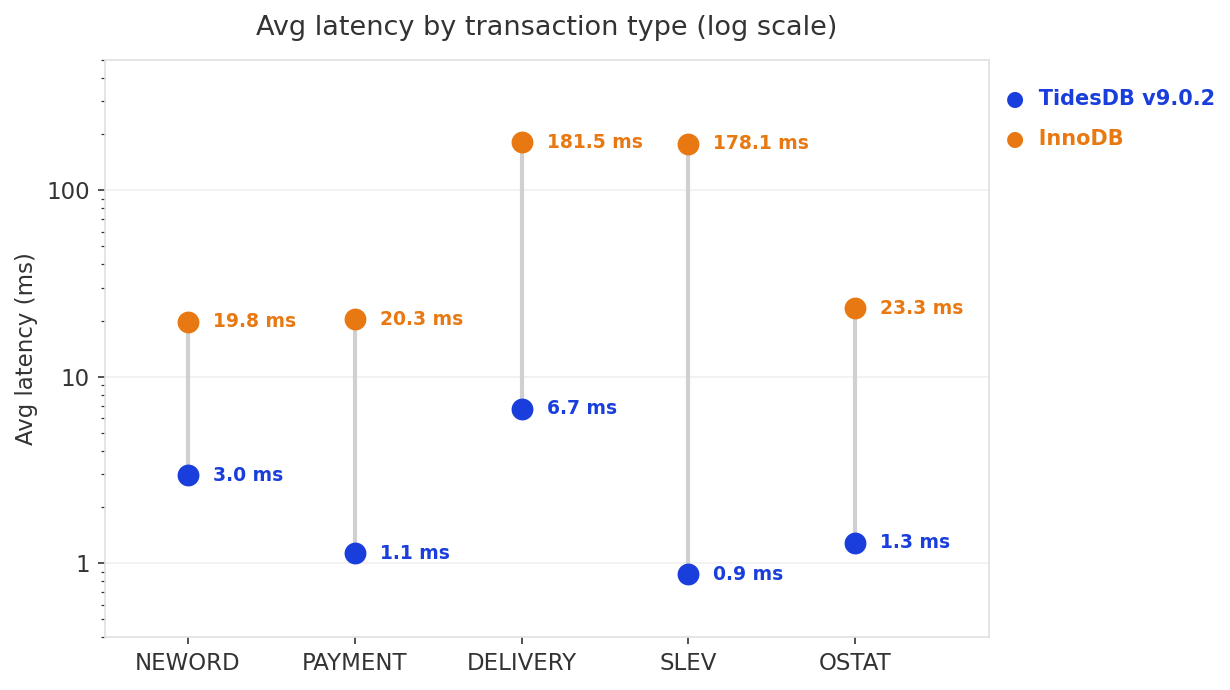
TidesDB’s DELIVERY avg is 6.7ms vs InnoDB’s 182ms, a 27x difference. SLEV is 205x faster at the average. Even NEWORD, a write-heavy transaction, is 6.7x faster.
No deadlocks were observed in the peak run. The first run saw one (Got error 149 Lock deadlock; Retry transaction) with no effect on final numbers. TideSQL was not configured for pessimistic locking.
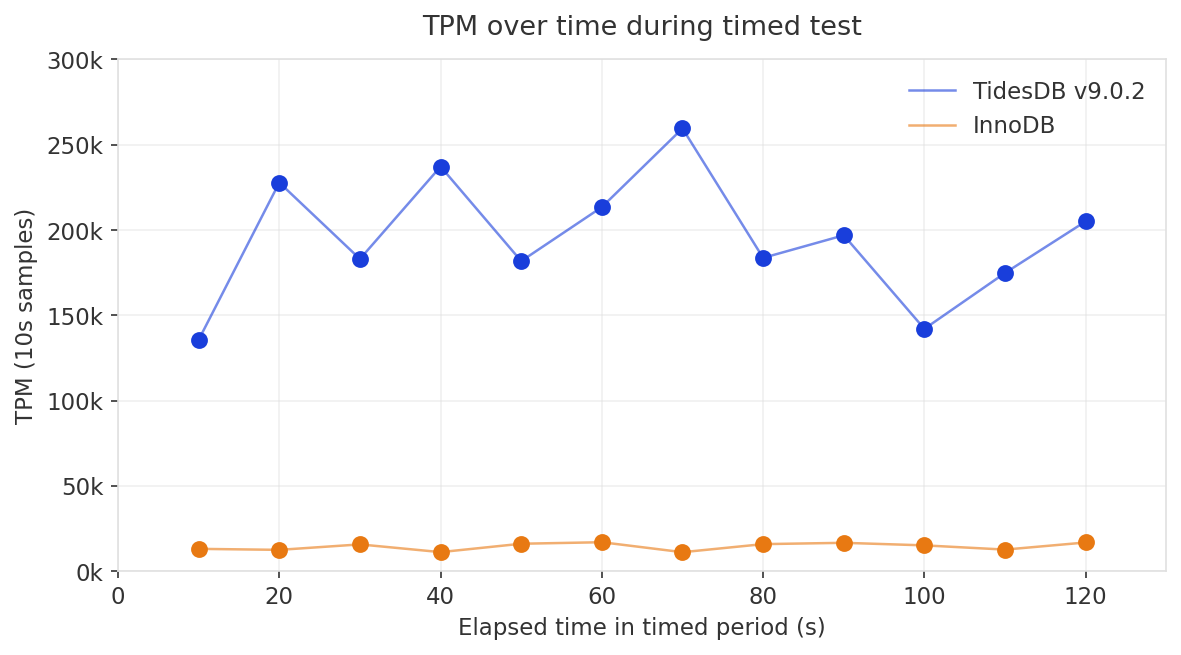
In the previous article, TidesDB v9.0.0 hit 84,009 NOPM on the same 64MB cache config but with 16 virtual users (Run 2). v9.0.2 peaks at 85,888 NOPM with 8 virtual users, half the concurrency, 102% of the throughput. Per-VU throughput more than doubled.
InnoDB’s numbers are rather consistent at 6,013 NOPM at 16 VUs previously, 6,308 at 8 VUs here. InnoDB was already bottlenecked on I/O at this cache size regardless of concurrency.
The v9.0.2 patch targeted the read path primarily focusing on block deserialization, cache bypass, comparator overhead, and iterator mechanics. Under a 64MB cache with a few gigabytes working set, these are exactly the functions that dominate. The profile confirms the hot path is now flat and distributed rather than concentrated in allocation and hashing. At 13.6x InnoDB’s throughput with half the threads, the patch landed where it mattered.
That’s all for now, thank you for reading!
—
| File | SHA-256 |
|---|---|
| hammerdb_logs_20260401_155404_inno.zip | 35fb841f7c6c3b6eb29a33e54c5788f310256d1a7cd3ccfe53162a27942cdfeb |
| hammerdb_logs_20260401_174757_tides.zip | 4770c35d98885e875c7f67bc41b13db07f8a2b660b9ae138550b5adf6810a540 |
| hammerdb_logs_20260402_025026_tides2.zip | 90f7c79ea8ed5fc642450bbe16cfbfc16c8e8952f5aafbddfd0d198ac482f185 |
| my.cnf | 6e53cd4da48901a7a3f9b26a9ce81c35b0363dbff1ba9d208865ec108aa512d3 |