TidesDB & RocksDB on NVMe and SSD

by Alex Gaetano Padula
published on January 26th, 2026
Recently, a contributor to TidesDB, @dhoard, ran a set of benchtool experiments on his NVMe disks. He reported is findings in our Discord and I decided to compare to my SSD runs as their running the same benchtool runners. Thus, the results are directly comparable.
The results clearly show a shift in usualbottlenecks rather than just raw speedups.
Memory footprint vs DB size
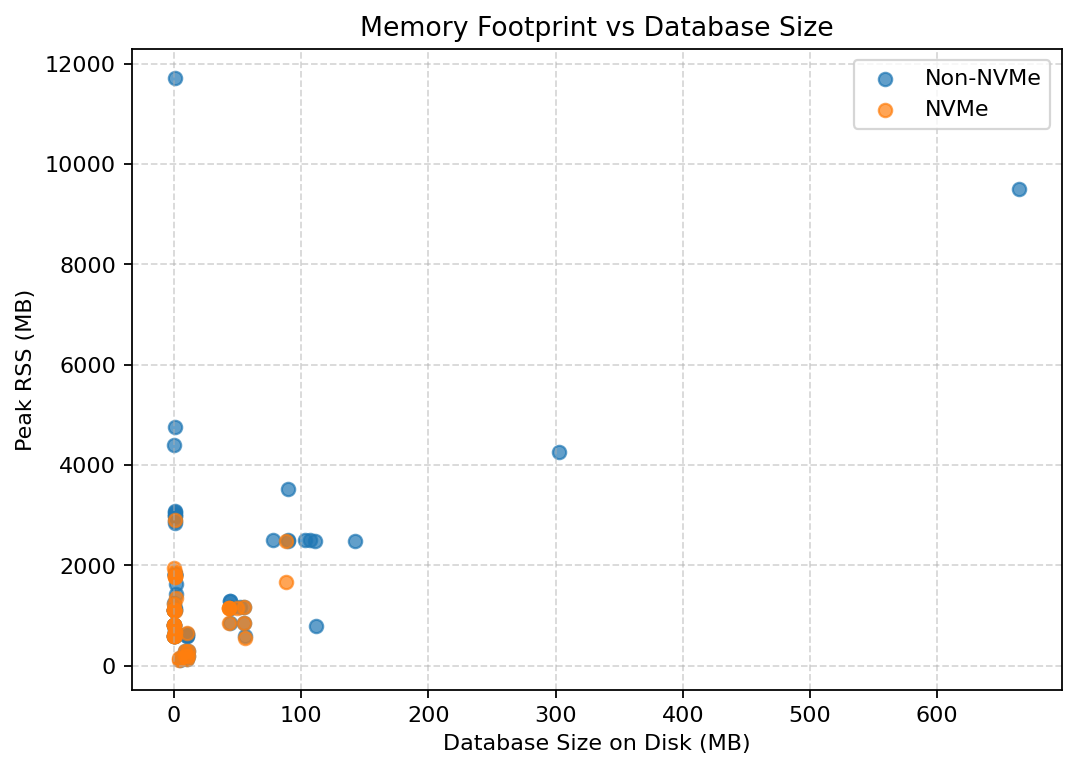
Across both NVMe and SSD runs, memory usage scales predictably with database size. There is no evidence of memory blow-up when moving to NVMe.
This indicates that improved performance on NVMe is not coming from increased caching or buffering, but from faster storage interaction. The layering between storage, cache, and execution remains intact.
Read latency distributions (p50 / p95 / p99)
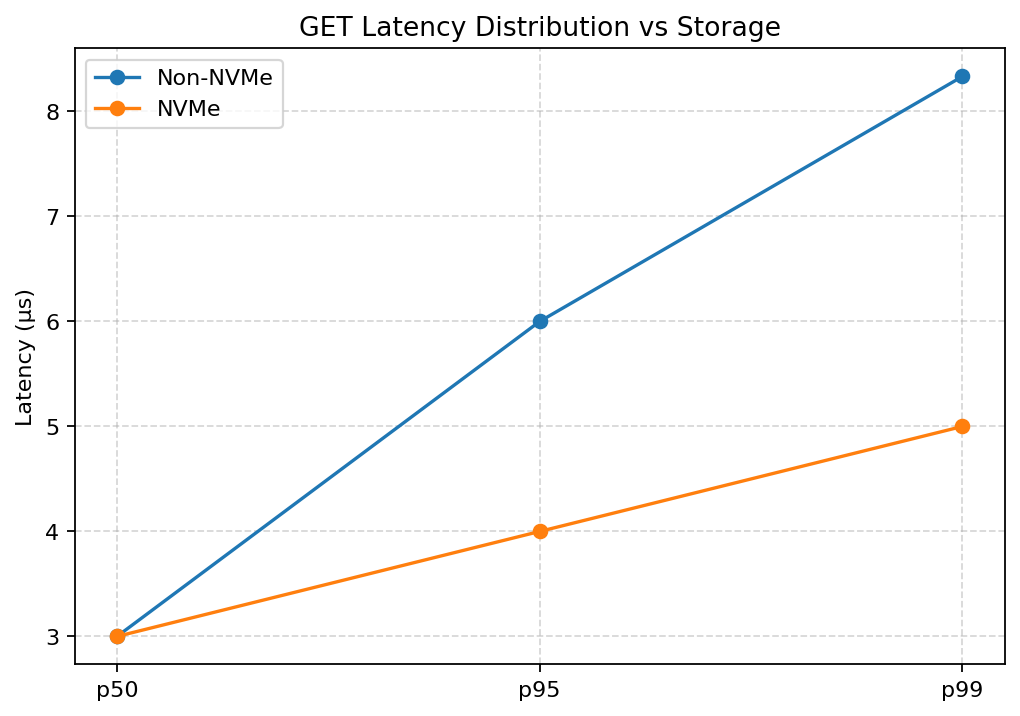
NVMe reduces median read latency, but the more important effect is on the tail. Both p95 and p99 latencies are lower compared to SSD.
This suggests NVMe primarily reduces long tail events in the read path. Fewer slow operations translate into tighter latency distributions and more predictable performance.
Iterator vs GET sensitivity to storage
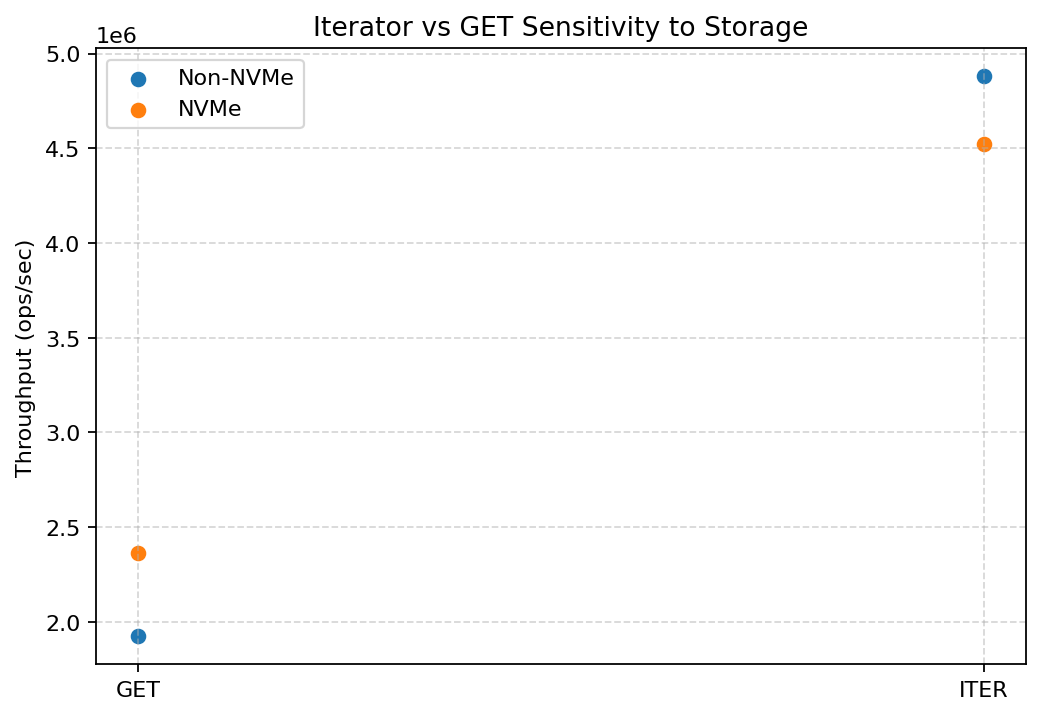
Iterator workloads benefit more from NVMe than GETs.
These paths are more sensitive to storage latency, and NVMe disproportionately improves them.
The result is higher iterator throughput and lower variance under NVMe.
Throughput vs thread count (scaling behavior)
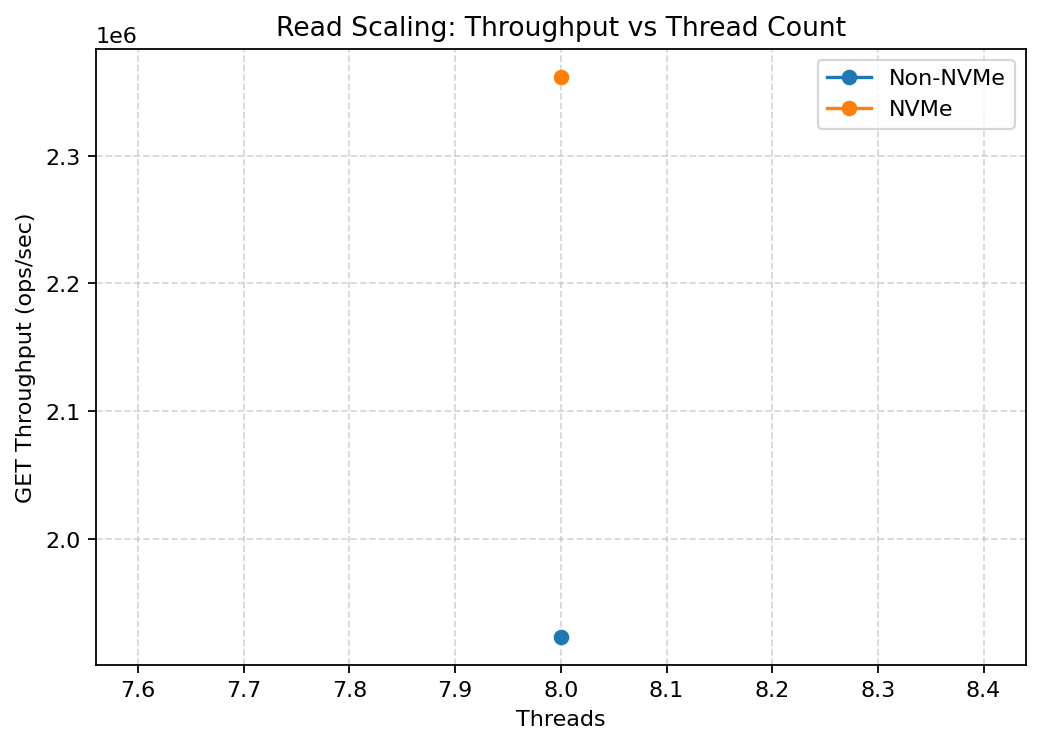
On SSD, throughput plateaus early as thread count increases. The system becomes I/O-bound before CPU resources are fully utilized.
On NVMe, throughput continues to scale with additional threads. This indicates a bottleneck shift from storage to CPU and coordination, which is the desired regime for modern systems.
Disk bytes written vs logical bytes (write amplification)
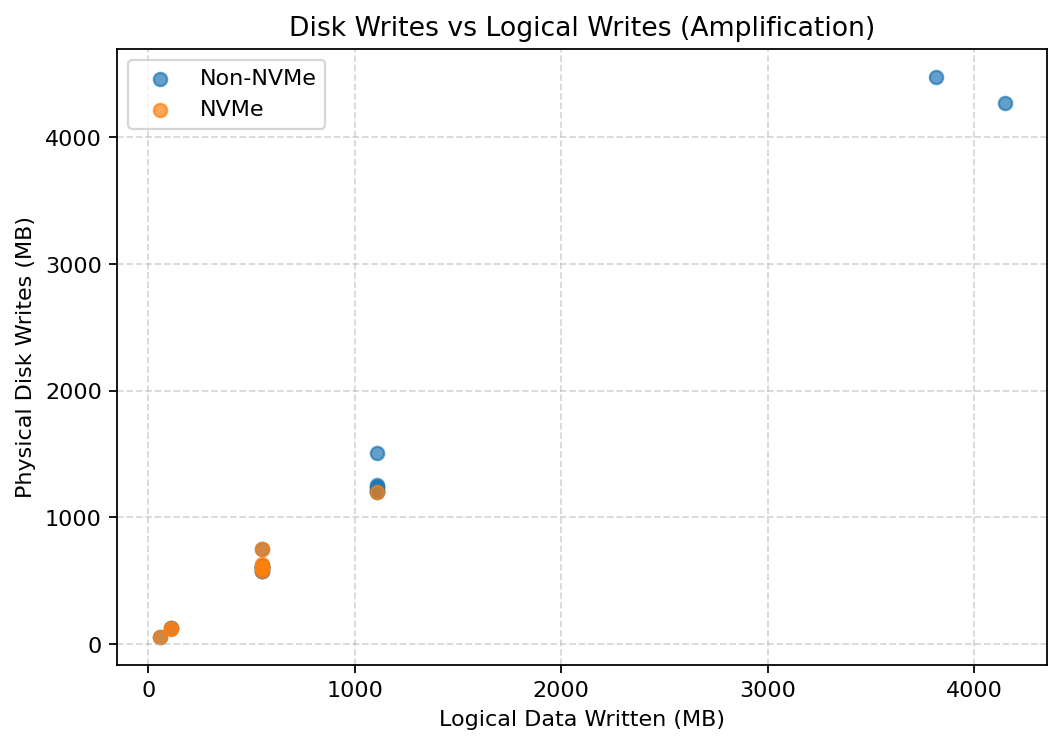
Higher throughput on NVMe does not come at the cost of increased write amplification.
Physical disk writes track logical writes closely in both environments. NVMe enables faster progress through the same work, not more work.
This confirms that performance gains are not due to hidden I/O debt.
Per-workload behavior
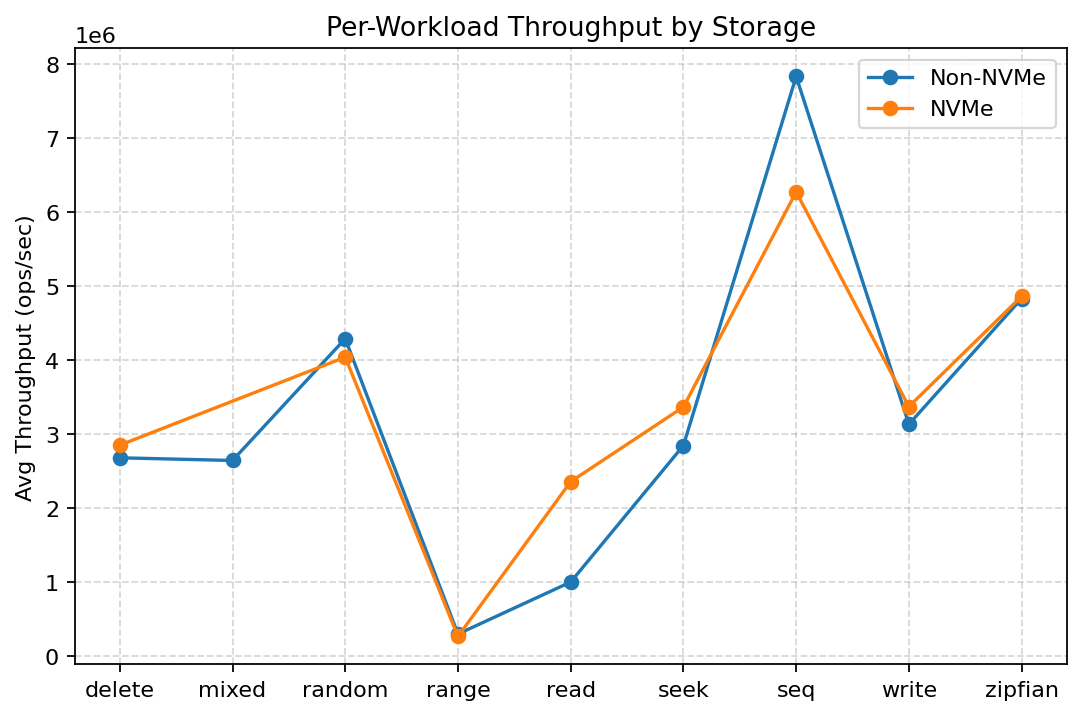
Different workloads respond differently to faster storage.
Read-heavy and seek-heavy workloads benefit the most from NVMe, while write and delete workloads see more modest gains. This reflects the different sensitivity of execution paths to storage latency.
The system does not behave uniformly, which is expected and healthy.
NVMe overview TidesDB & RocksDB
In the most recent benchmark run, both TidesDB and RocksDB were evaluated on the same NVMe hardware (thanks to Doug). This allows a direct comparison between engines under identical storage conditions, and also a comparison against earlier RocksDB results collected on SSD.
On NVMe, both engines benefit from reduced storage latency, but the way they benefit differs.
TidesDB shows strong gains in both read and write throughput, with performance scaling cleanly as storage stops being the primary bottleneck. The results are consistent with earlier observations: NVMe shifts TidesDB into a CPU- and coordination-bound regime without increasing write amplification or memory usage.
RocksDB also improves on NVMe relative to SSD, particularly for reads. However, the improvement is less uniform across workloads, and write throughput shows smaller gains relative to TidesDB under the same conditions.
Comparing RocksDB on NVMe to its earlier SSD results highlights a familiar pattern - faster storage improves peak throughput, but does not fundamentally change internal amplification or scaling behavior.
Overall, the NVMe results reinforce the earlier conclusions TidesDB benefits structurally from faster storage, while maintaining predictable resource usage and low amplification, and the performance gains are not the result of workload-specific tuning or caching artifacts.
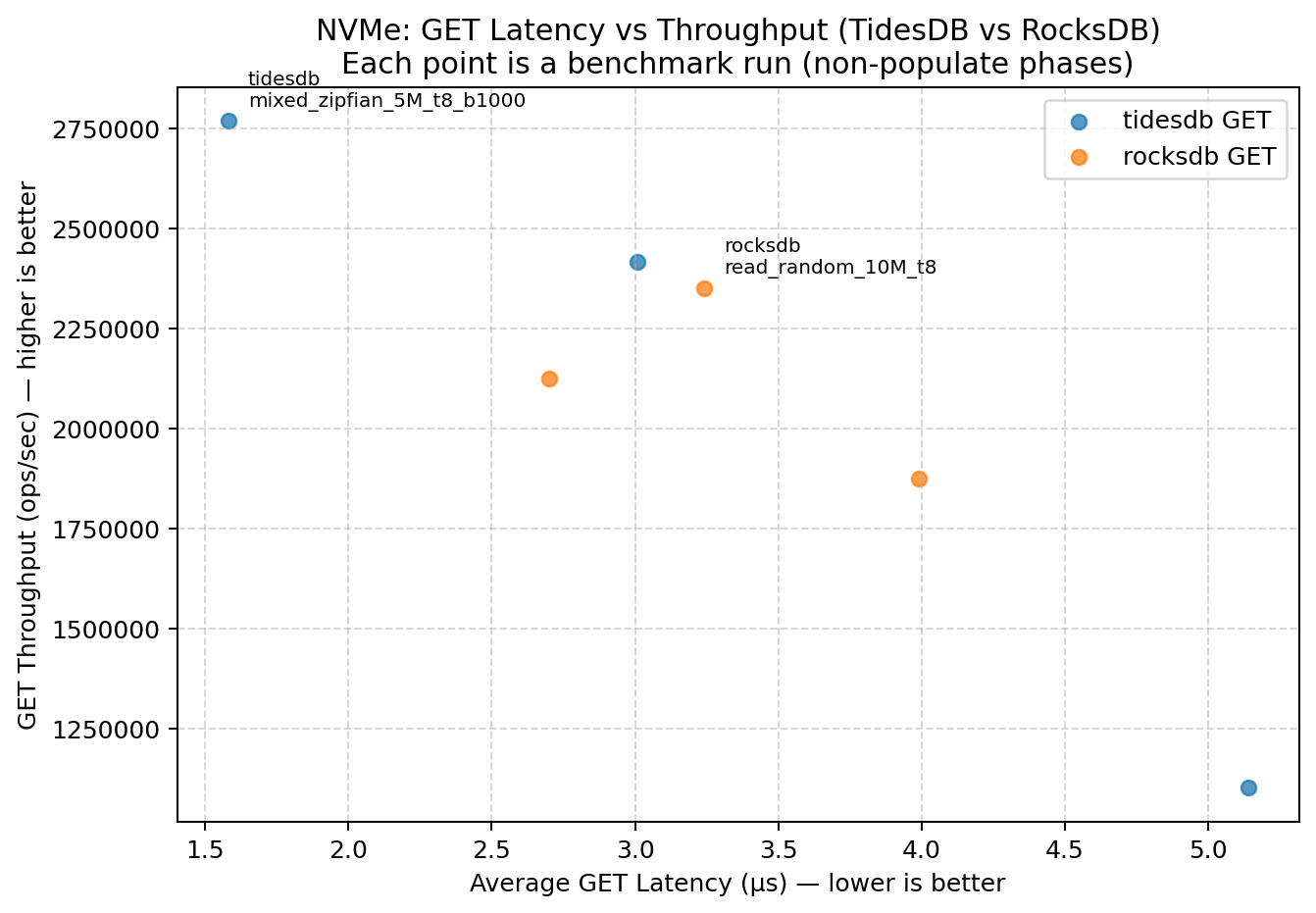
This plot shows the tradeoff surface for point reads (GET) - each point is a benchmark run, with lower latency and higher throughput preferred. On NVMe, both engines move into a less I/O-bound regime, and the separation between engines becomes visible as a latency/throughput frontier.
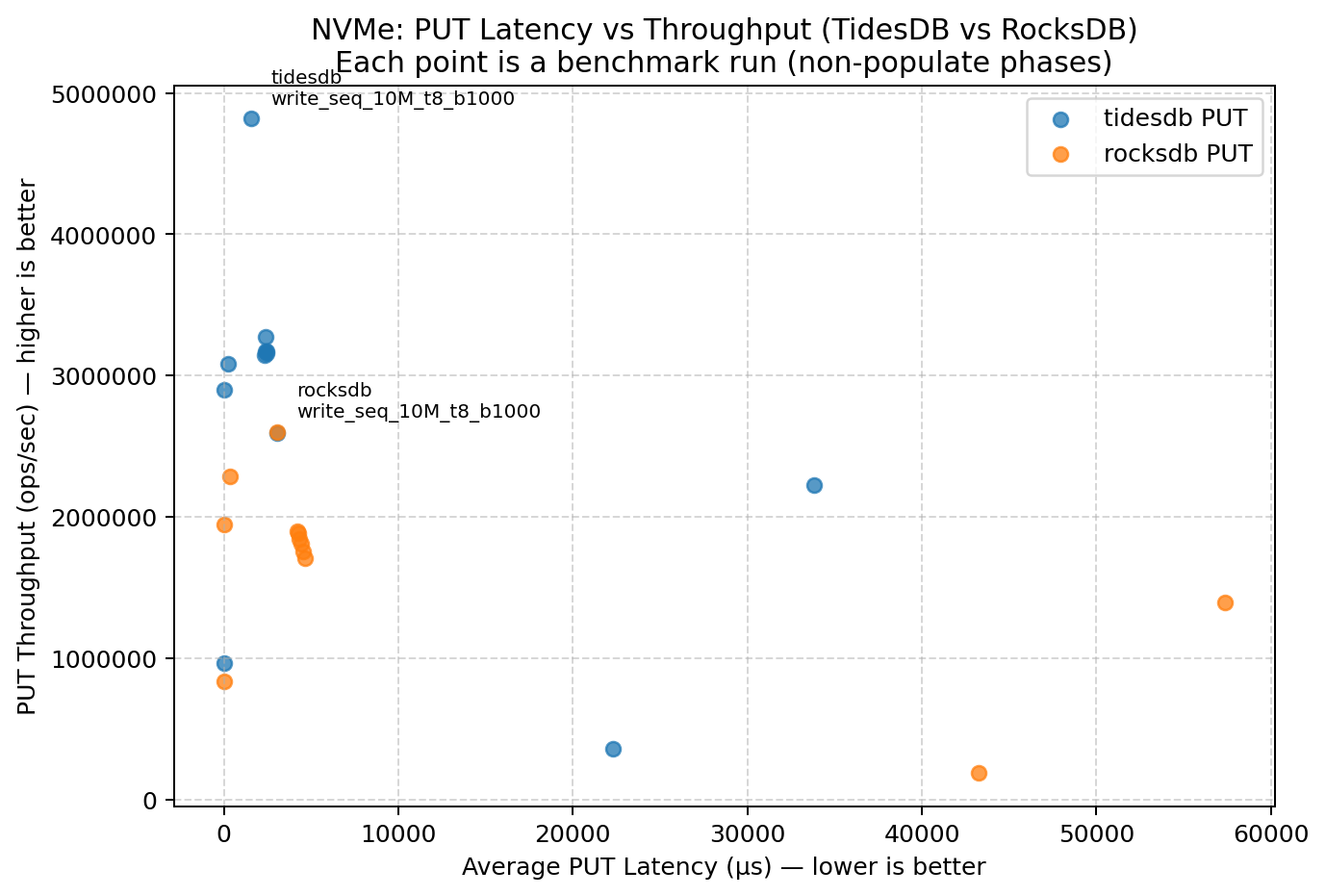
For writes (PUT), NVMe reduces stalls and tightens the latency/throughput spread. This highlights not just peak throughput, but how stable throughput remains as latency varies across workloads.
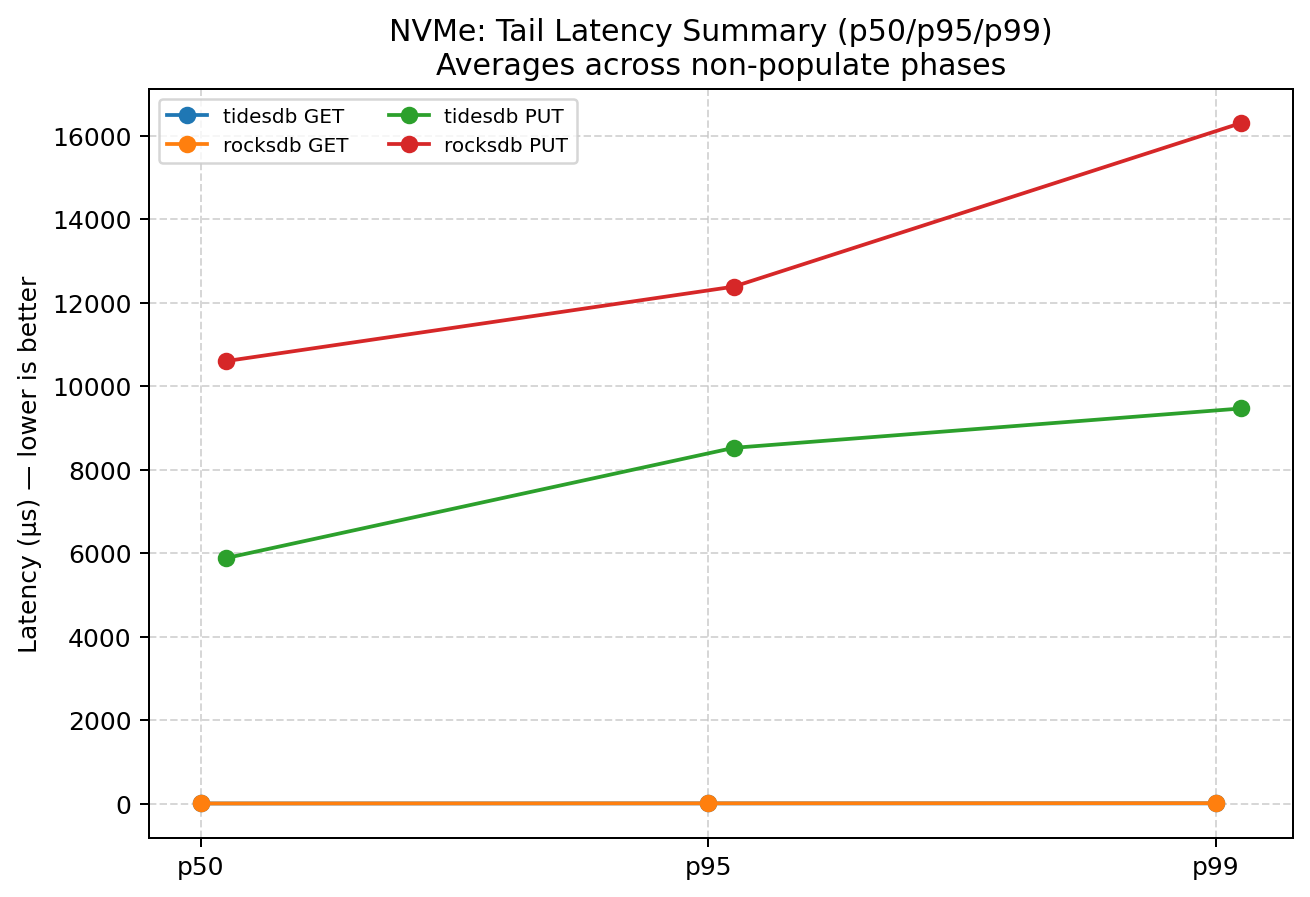
Tail latency (p95/p99) provides a better signal than averages when background work (flush/compaction) is active. This summary compares p50/p95/p99 for both GET and PUT across the same NVMe run.
Summary
The primary effect of NVMe on TidesDB is not raw speed, but changing where the system spends time.
- Tail latencies are reduced
- Iterator and metadata-heavy paths improve significantly
- Scaling shifts from I/O-bound to CPU-bound
- Resource utilization remains stable and predictable
- Write amplification stays low
These results suggest that TidesDB benefits from NVMe in a structurally sound way, without compromising efficiency or correctness.
Environments
SSD
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
NVMe
- Ryzen 7 7700
- 128GB RAM
- NVMe WD_BLACK SN850X 1000GB
- Ubuntu 24.04.3 LTS
Software versions used
- TidesDB v7.4.0
- RocksDB v10.9.1
You can download the CSV files used in this analysis here:
TidesDB & RocksDB
Thank you again to @dhoard for running and sharing these benchmark results.