TidesDB Differences with glibc, mimalloc, tcmalloc

published on January 28th, 2026
I thought today I would benchmark TidesDB with glibc, mimalloc, and tcmalloc with a new benchtool script runner that’s rather automated to see how the system would react running a variety of workloads.
Allocator behavior can affect throughput, contention, batching, and tail latency in a storage engine. These benchmarks aim to show where allocator choice meaningfully impacts TidesDB workloads and where it has little effect.
Environment
- Intel Core i7-11700K (8 cores, 16 threads) @ 4.9GHz
- 48GB DDR4
- Western Digital 500GB WD Blue 3D NAND Internal PC SSD (SATA)
- Ubuntu 23.04 x86_64 6.2.0-39-generic
- TidesDB v7.4.2
PUT throughput scaling vs threads
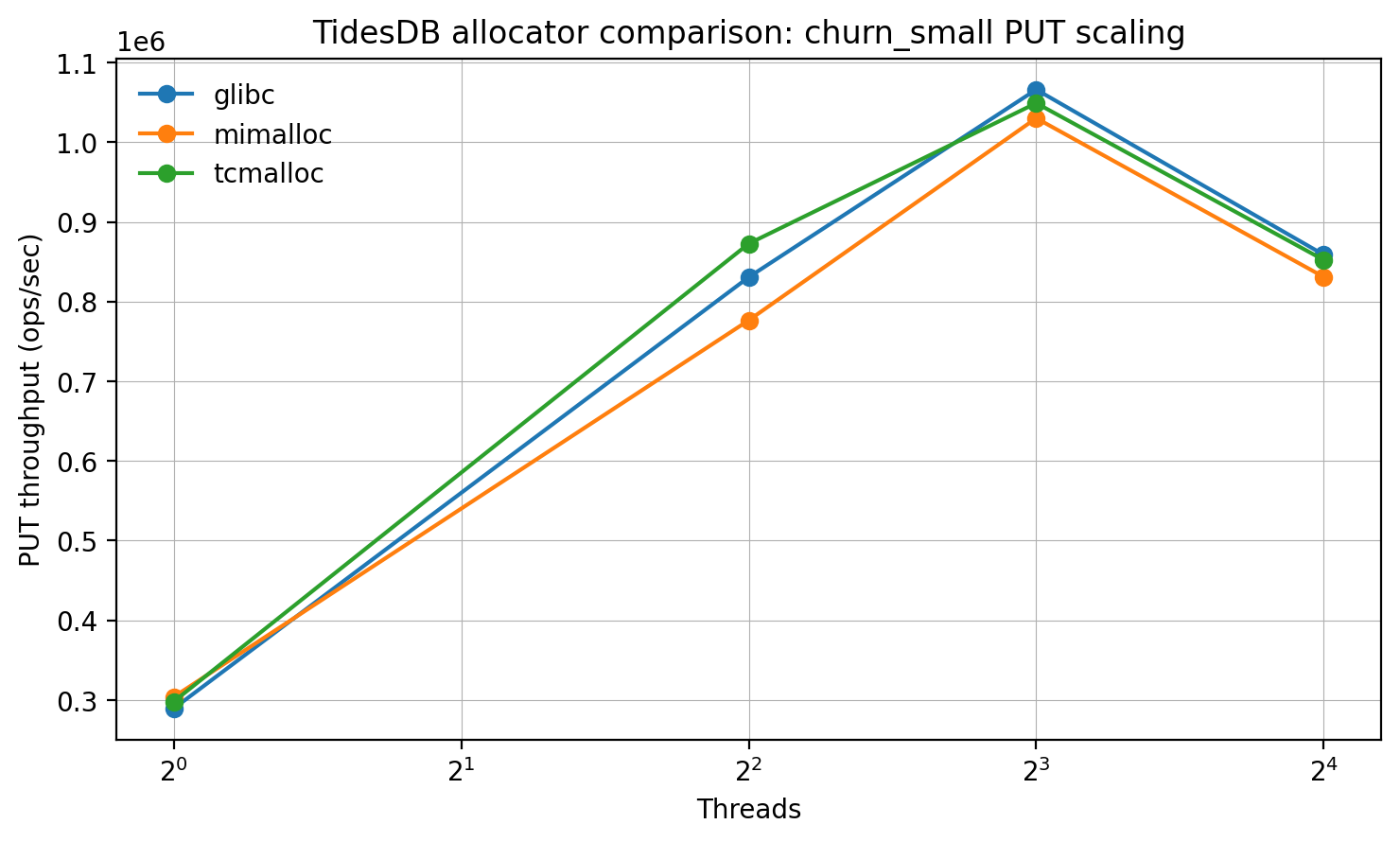
First up, this plot shows scaling from 1-16 threads on a small churn write-heavy scenario. All three allocators scale similarly up to 8 threads, with glibc slightly ahead at 8 threads (~1.07M ops/s) vs tcmalloc (~1.05M) and mimalloc (~1.03M). At 16 threads, all drop, but glibc remains marginally highest (~0.86M) with tcmalloc close (~0.85M) and mimalloc slightly lower (~0.83M). This seems like allocator choice is secondary to the workload’s own contention/limits here.
PUT contention throughput scaling vs threads
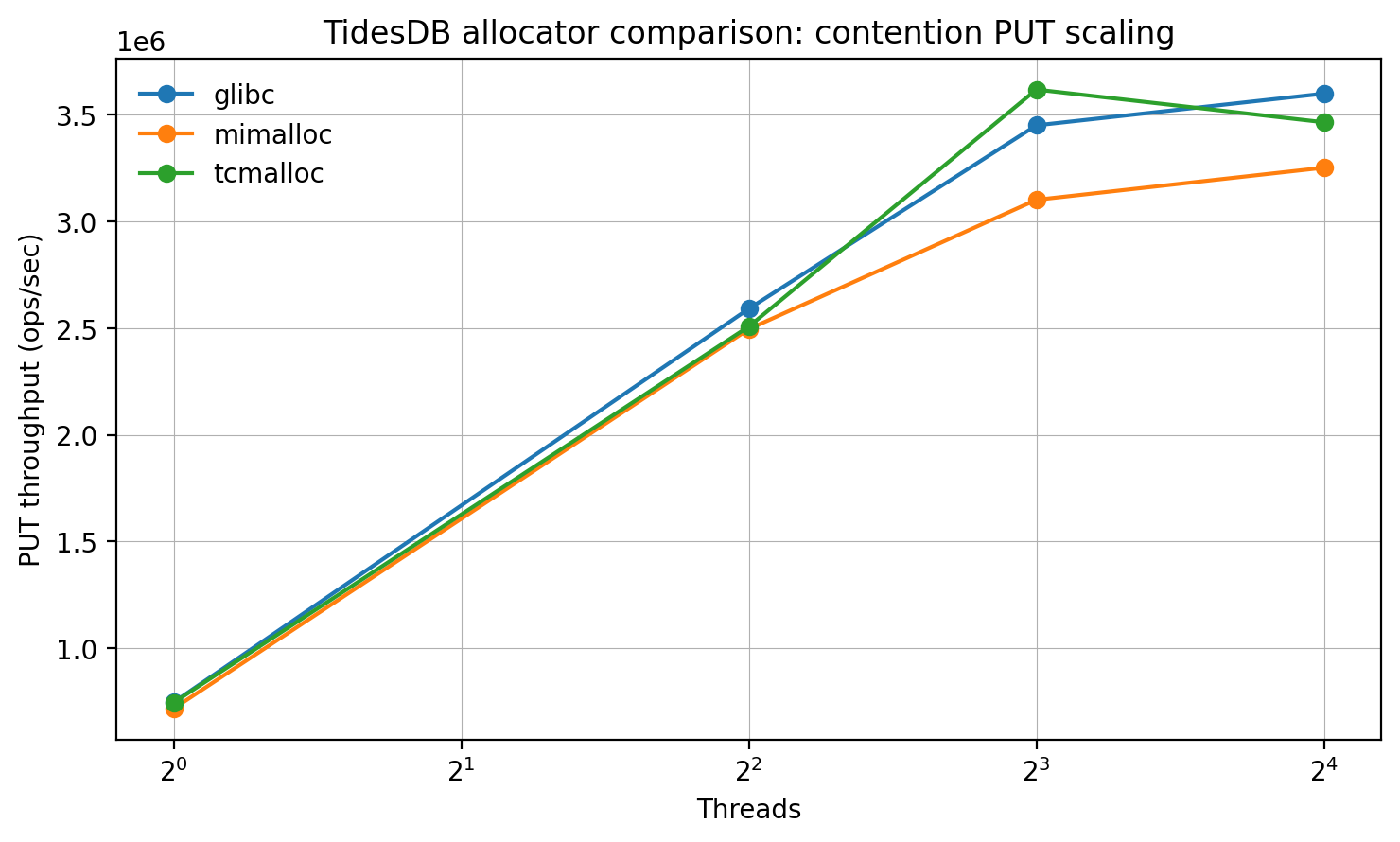
Second plot, under explicit contention, the differences are clearer at higher thread counts. At 8 threads, tcmalloc leads (~3.62M ops/s) vs glibc (~3.45M) and mimalloc (~3.10M); at 16 threads, glibc becomes best (~3.60M), with tcmalloc (~3.46M) second and mimalloc (~3.25M) trailing. This pattern is consistent with allocator behavior mattering most when the workload stresses shared allocation/free paths.
Batch size vs PUT throughput (t8)
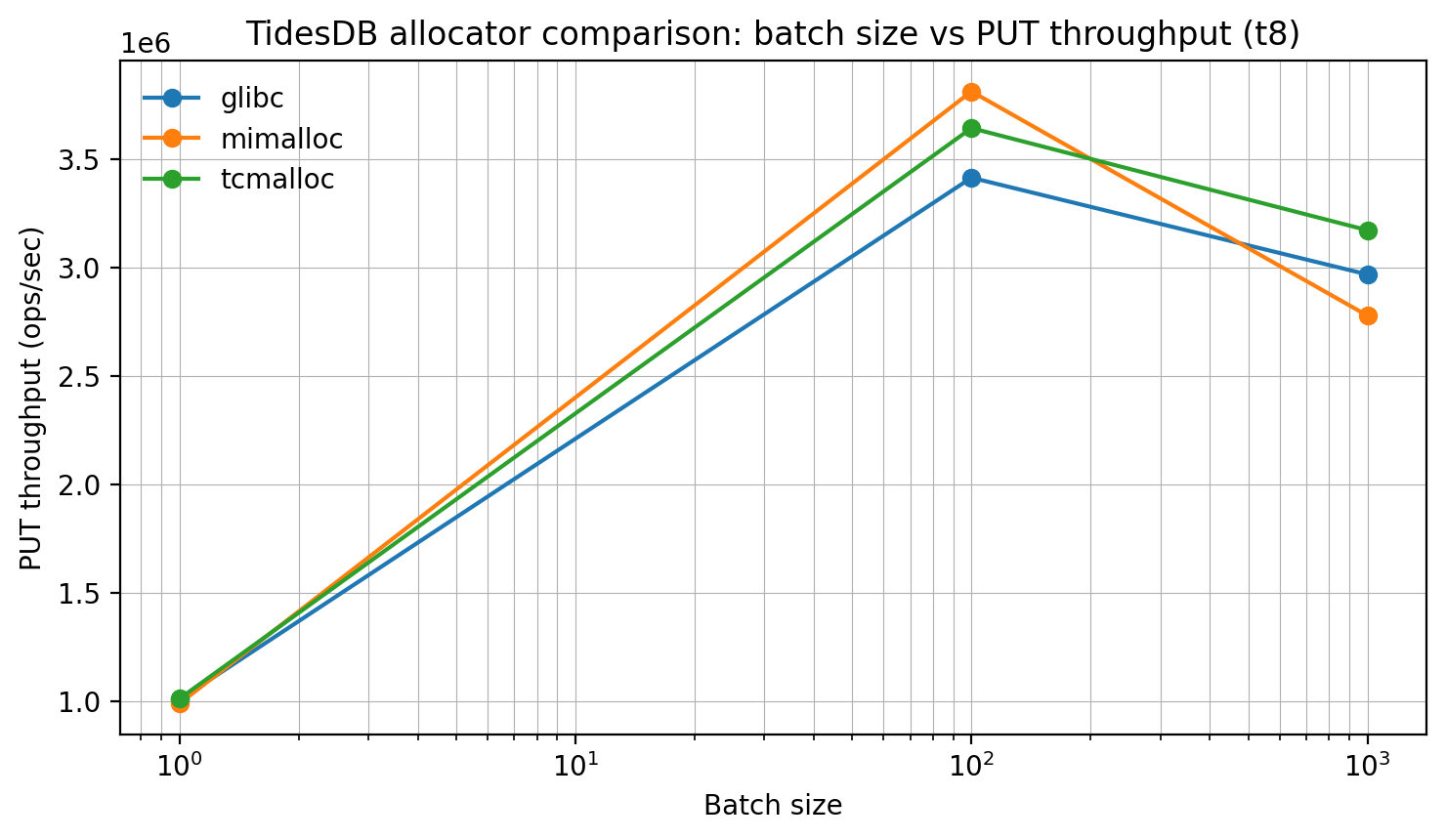
Next, batching dominates throughput, with a large gain when moving from batch=1 to batch=100. The peak is around batch=100, where mimalloc is highest (~3.81M ops/s), followed by tcmalloc (~3.64M) and glibc (~3.41M). At batch=1000, performance drops a bit for all, but tcmalloc holds up best (~3.17M) while mimalloc falls most (~2.78M). Interestingly, batching appears more impactful than allocator choice, but allocator can shift the peak and the drop-off.
Peak RSS vs threads (churn_small PUT)
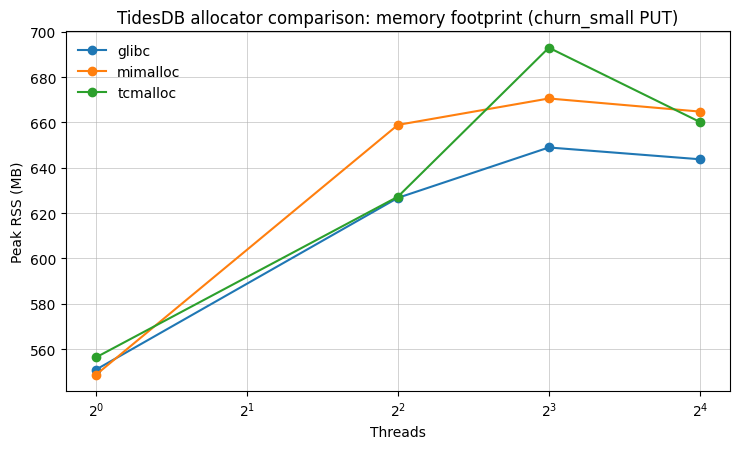
This plot shows peak resident memory (RSS) during the small-value churn write workload as thread count increases. At 1 thread, all allocators are similar (~550-560 MB). As concurrency rises, glibc stays consistently lower, while mimalloc trends higher at 4-16 threads and tcmalloc peaks around 8 threads. Overall, allocator choice can shift the memory footprint by a few tens of megabytes under churn-heavy concurrency, but the differences remain modest relative to the workload’s baseline memory use.
Large value PUT p99 tail latency (t8)
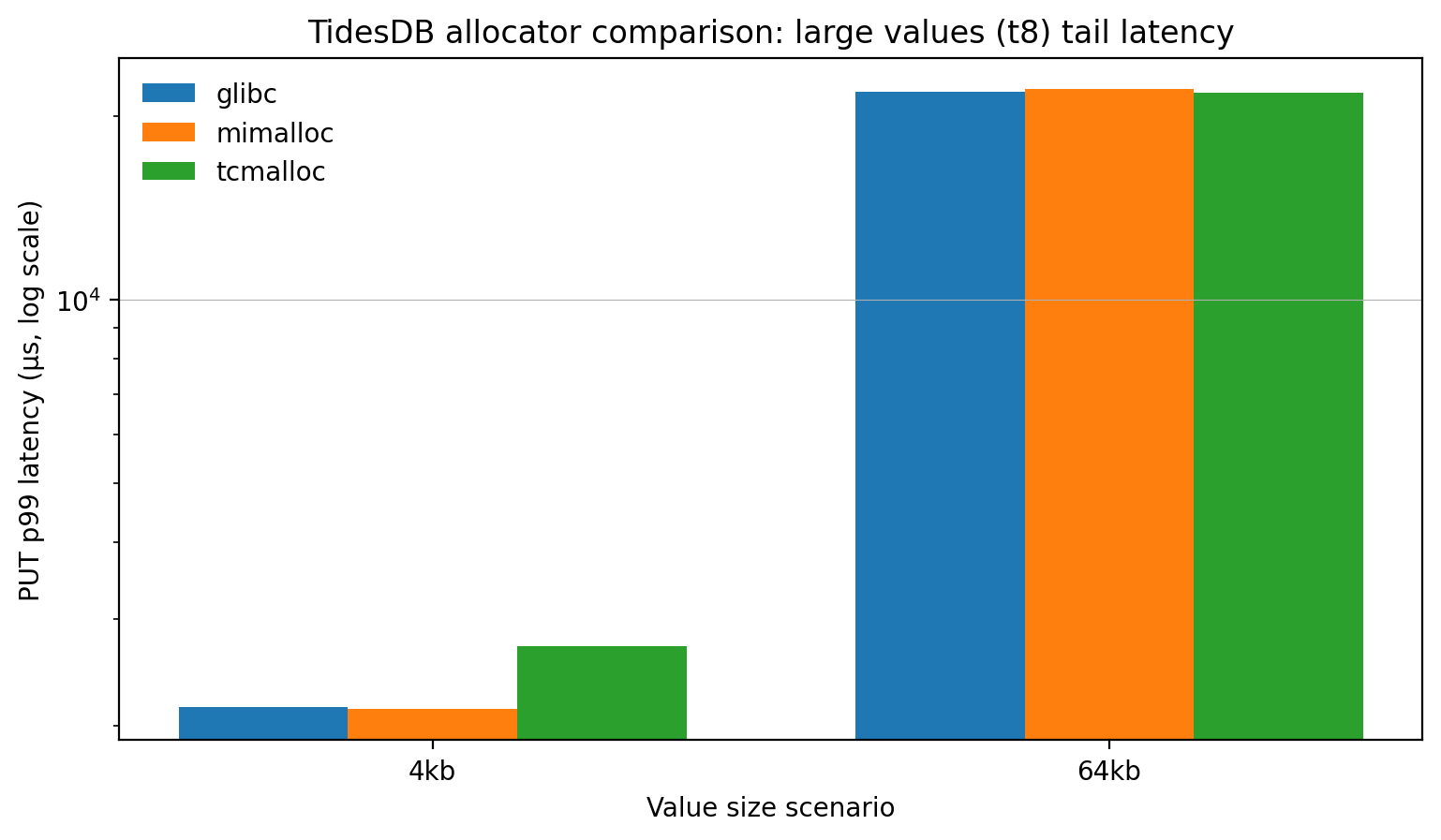
Finally, for 4KB values, glibc and mimalloc have similar p99 (~2.13-2.15 ms) while tcmalloc is worse (~2.70 ms). For 64KB values, all are very close (~21.8-22.1 ms p99). Allocator choice does seem to affect tail latency more noticeably at “medium” payload sizes (where allocator overhead is non-trivial), while at very large payloads the cost is dominated elsewhere internally.
Across these benchmarks, allocator choice affects TidesDB performance in specific scenarios, most notably under contention and with moderate payload sizes, but remains secondary to batching and overall workload structure. glibc stays competitive and often leads at higher thread counts, tcmalloc performs well under contention but shows weaker tail latency for mid-sized values, and mimalloc favors batch-heavy workloads but degrades at very large batch sizes.
In practice, tuning column family, database configuration, and workload patterns yields larger gains than changing allocators alone, though allocator choice can still affect high-concurrency performance.
Thanks for reading!
You can find the raw reports below:
Raw plain text results (more thorough):