How does TidesDB work?
If you want to download the source of this document, you can find it here.
Introduction
This document explains how TidesDB works, from the idea it is built on down to the bytes on disk. It is organized so that understanding accumulates: each section relies only on what came before it. We start with the whole system in miniature, then name its parts, and only at the end open up the on-disk formats, the modules that implement everything and testing mechanics.
TidesDB is an embeddable key-value storage engine built on the log-structured merge tree, or LSM tree. The LSM tree rests on one old and well-understood bargain. Random writes scattered across a large sorted structure on disk are slow, because each one forces a seek and a rewrite. So instead of writing in place, an LSM tree batches writes in memory and then flushes them to disk all at once, as a sorted run. Writes become fast and sequential.
Nothing is free, and the bargain has two costs. The first is write amplification: the same data is rewritten several times as those sorted runs are later merged together. The second is read amplification: a single lookup may have to search several sorted runs before it finds the key, because the newest copy could be in any of them. Much of what follows is machinery for keeping both costs small.
On top of that foundation, TidesDB adds what a production engine needs: ACID transactions with five isolation levels, and data organized as a hierarchy of sorted files called sorted string tables, or SSTables. The hierarchy is arranged in levels, each holding roughly N times more data than the level above it. A background process called compaction continually merges SSTables from adjacent levels, throwing away obsolete entries and reclaiming space as it goes.
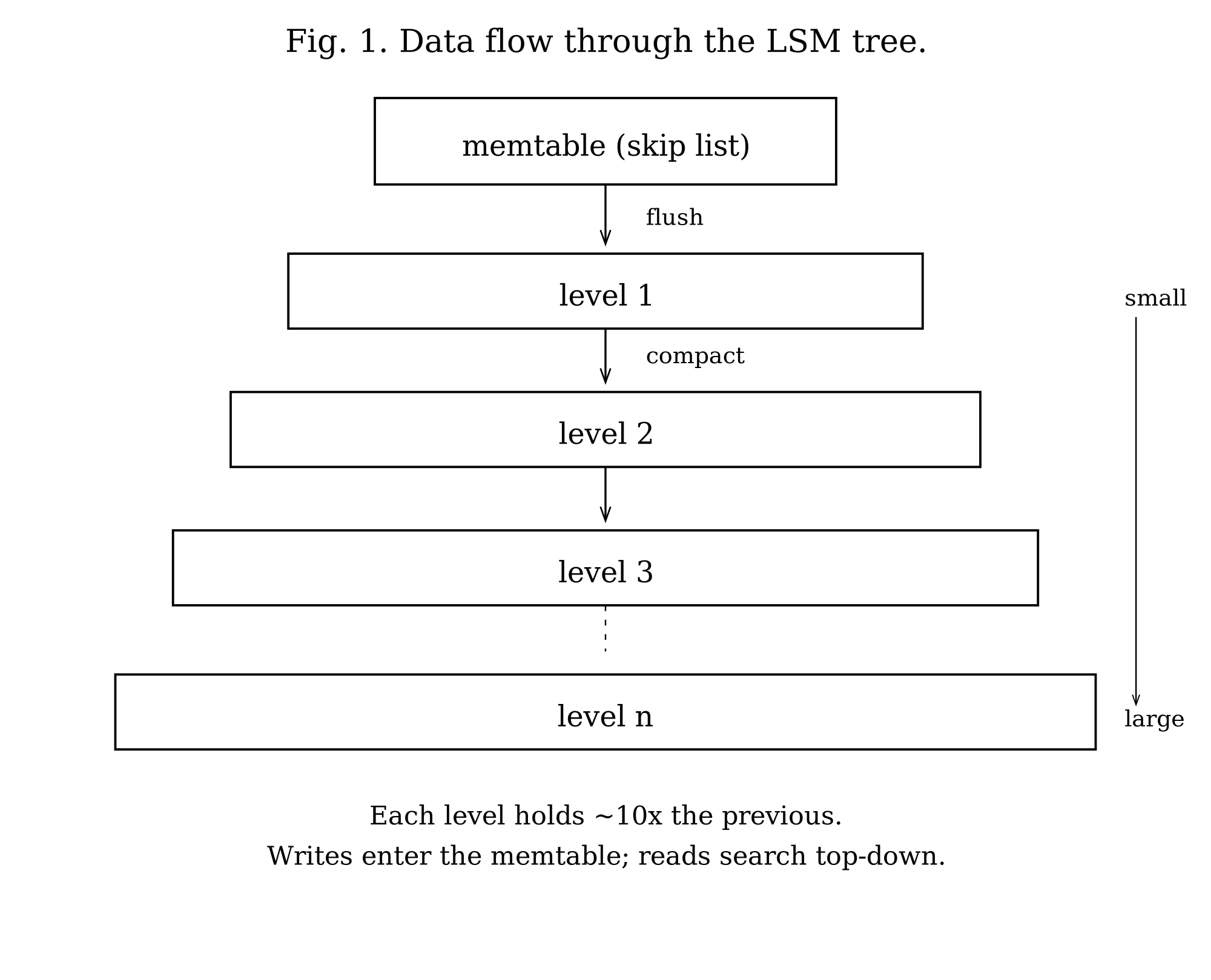
Here is the whole lifecycle of a piece of data in one paragraph (Figure 1). A write first lands in a structure called a memtable, which comprises a sorted data structure called a skip-list and a block-managed WAL, known as a write-ahead log. The write is appended to the WAL and then the skip-list, so it survives a crash. When the memtable grows past a configured write buffer size, it is frozen and made immutable, and a background worker writes it to disk as an SSTable at the top level of the hierarchy. SSTables accumulate there, and compaction merges them downward into larger, deeper levels. A read walks this same structure from newest to oldest and stops at the first copy of the key it finds. Everything else in this document is a refinement of that loop.
(TidesDB builds its memtable from a skip list rather than a balanced tree. The reasons are practical: a skip list is simpler to implement correctly, and its structure lends itself naturally to lock-free concurrent access. The Skip List section returns to this once the rest of the system is in view.)
The Data Model
Before following a write or a read through the system, we need names for the parts. This section introduces them at the level of what each thing is and why it exists. The exact byte layouts are deferred to On-Disk Format, once the parts have been seen in motion.
Column Families
A TidesDB database is divided into column families. A column family is an independent key-value namespace: it has its own configuration, its own memtables and write-ahead logs, and its own levels of SSTables on disk. The isolation between them is complete, which is what lets two column families in the same database use entirely different compression algorithms, key orderings, and tuning parameters.
In the default mode, each column family owns one active memtable that receives new writes, a queue of frozen memtables waiting to be flushed, a write-ahead log paired with each memtable, up to 32 levels of SSTables on disk, and a manifest that records which SSTables belong to which level. There is also an alternative arrangement, the unified memtable, in which all column families share a single memtable and a single log; it solves a specific write-amplification problem and is covered with the write path, under Unified Memtable.
The Memtable
The memtable is where writes live with a write ahead log before a sorted run creates an SSTable pair.
Sorted String Tables
An SSTable is an immutable sorted run of key-value pairs on disk. Once written, it is never modified; it is only ever read, or eventually replaced by compaction. Immutability is what makes the whole system safe to read concurrently without locks.
Three properties of an SSTable matter for everything that follows (Figure 2). First, its entries are sorted by key, so the engine can binary-search within it. Second, it carries a small bloom filter — a compact probabilistic structure that can say “this key is definitely not here” without touching the data, which lets a lookup skip most SSTables outright. Third, it carries a block index that maps key ranges to positions in the file, so a lookup can jump near the right place instead of scanning from the start.
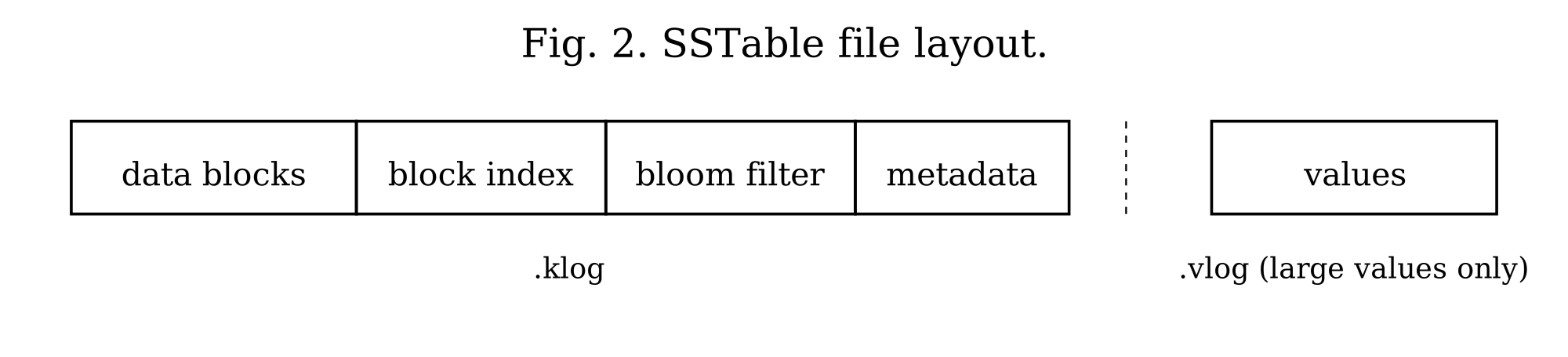
An SSTable is physically two files: a key log holding keys and small values, and a value log holding large values off to the side. Small values are stored inline with their keys; values at or above a threshold (512 bytes by default) are written to the value log, and the key log keeps only an offset pointing to them. This split keeps the key log compact and fast to scan during lookups and iteration, while still accommodating values of any size. The key log is divided into compressed blocks of about 64KB, and the bloom filter and block index sit at the end of it. (The exact framing of all this — entry layout, block structure, how the bloom and index are serialized — is in On-Disk Format.)
A column family may optionally store its key log as a B+tree instead of the default block layout. The trade is more work at flush time in exchange for faster point lookups and faster seeks into the middle of a table, which suits workloads dominated by random reads. The two formats are interchangeable from the rest of the engine’s point of view; the B+tree’s structure and serialization are described in On-Disk Format.
Levels
SSTables are organized into a hierarchy of levels, numbered from the top. A flush always produces an SSTable at level 1. Compaction merges level 1 into level 2, level 2 into level 3, and so on, with each level holding roughly N times more data than the one above it (N is configurable, default 10). The deeper a level, the larger and older its data. This shape is the source of the read-amplification cost from the introduction: a key could live in any level, so a lookup may have to check several of them. The bloom filters and block indexes are what keep that check cheap, and compaction is what keeps the number of levels small. How the levels are searched is the subject of the Read Path; how they are kept in balance is the subject of Compaction.
Transactions and Visibility
Many threads read and write a TidesDB database at once, and a reader must see a consistent picture even while writers are changing it. This section explains how. It comes before the write and read paths because both of them constantly refer to the machinery built here: snapshots, sequence numbers, and version chains. TidesDB is fully ACID and offers five isolation levels, from Read Uncommitted to Serializable, all built on a single underlying mechanism — multi-version concurrency control.
Multi-Version Concurrency Control
The core idea is that the engine never overwrites a value in place. Instead, each write creates a new version of the key, stamped with a sequence number, and the versions for a key form a chain ordered newest-first (Figure 3). A reader does not see “the value”; it sees the newest version whose sequence number is at or below its own snapshot. Writers add versions while readers walk the chain, and neither blocks the other.
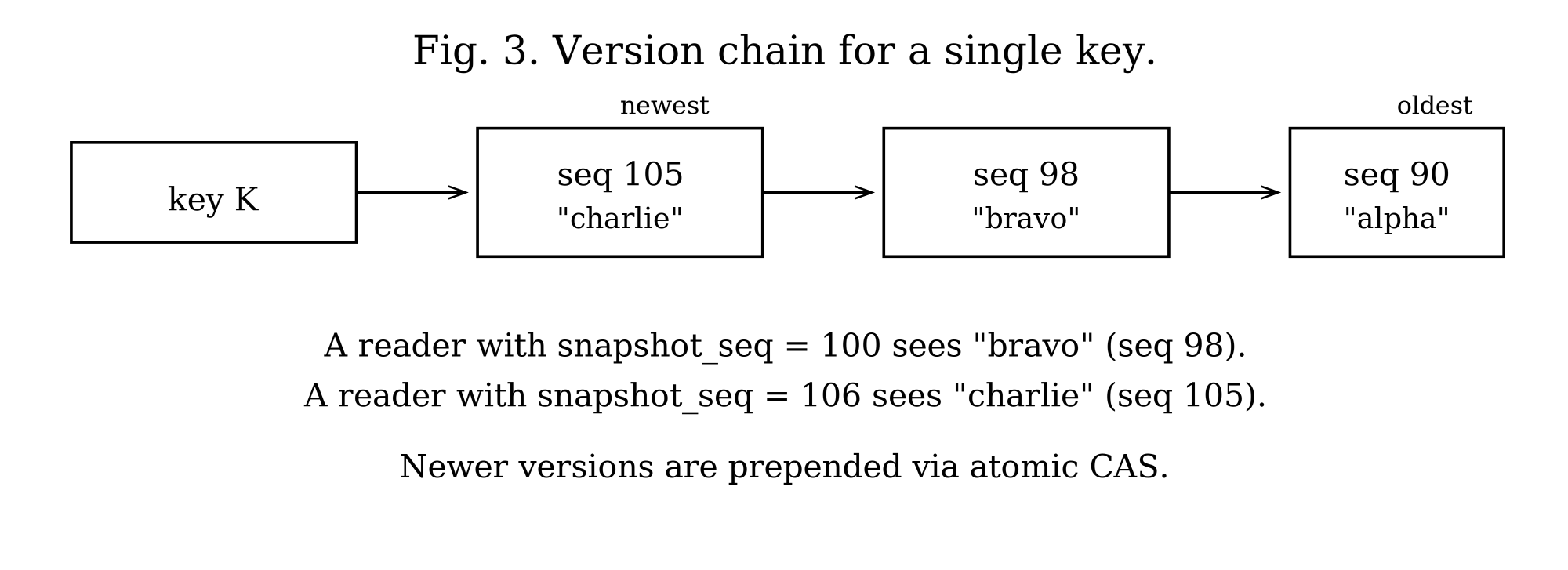
Every transaction is given a snapshot sequence number when it begins, and that number defines what it can see. The rule for choosing it depends on the isolation level: Read Uncommitted uses the maximum possible value so it sees everything, including uncommitted writes; Read Committed refreshes its snapshot on every read so it always sees the latest committed data; and Repeatable Read, Snapshot, and Serializable take global_seq - 1, freezing their view at everything committed before they started.
A commit assigns a fresh commit sequence number from a single global atomic counter, writes the operations to the WAL, applies them to the active memtable under that sequence, and then marks the sequence committed in a fixed-size circular buffer (65536 entries). Readers consult that buffer and skip any version whose sequence is not yet marked committed, which is how a half-finished commit stays invisible. The buffer wraps, and the visibility check accounts for the wrap rather than risking a wrong answer: a sequence that has fallen more than the buffer size behind the high-water mark has had its slot recycled by a newer sequence, so the check treats it as committed. That is sound because a version only becomes visible to a reader after its commit applied it, and a sequence that far back cannot still be in flight — the same assumption recovery makes when it backfills only the trailing window. Without it, an old committed version would read its recycled slot as the newer sequence’s in-progress state, and a snapshot read would fall through to a stale older value.
Two refinements keep this correct under real workloads.
The first protects long-running readers. Compaction would like to throw away superseded versions, but a slow reader holding an old snapshot may still need one. So the engine tracks the minimum snapshot sequence held by any live reader and treats it as a floor: at every point where compaction or flush would drop a superseded version, it keeps any version whose sequence is at or above that floor. Without the floor, a long scan could watch a value vanish mid-iteration because a background merge decided the newer version was enough. The floor is recomputed at the start of every compaction and flush, so once a reader finishes — by commit, rollback, or being freed — the versions it was pinning become collectable by the next merge. Freeing a transaction also removes it from the active list as part of teardown, so a caller who frees without committing or rolling back cannot strand a dangling snapshot that compaction would later try to honor.
The second refinement extends the same guarantee to iterators. When an iterator is created, it captures its sources up front: the active memtable, the frozen memtables, and — in unified mode — every entry still sitting in the unified immutable queue. That last source matters because a flush worker may have frozen the shared memtable but not yet written its contents to SSTables; without snapshotting the immutable queue, the iterator would find those entries in neither memory nor on disk. With it, the iterator sees every committed write visible to its snapshot, no matter where on the flush pipeline that write currently sits.
The Five Isolation Levels
The five levels differ in how much they check at commit time, and that is the whole of the difference.
Read Uncommitted sees every version, committed or not. Its snapshot is the maximum sequence value.
Read Committed does no validation and refreshes its snapshot on each read, so it always reflects the most recently committed data.
Repeatable Read remembers every key it read, along with the version it saw. At commit it checks whether any of those keys gained a newer version in the meantime, and aborts if so.
Snapshot Isolation detects write-write conflicts only, with first-committer-wins. Two concurrent commits to the same key cannot both win: at commit, before anything is written, each write key claims a slot in a fixed reservation table, stamping it with a fingerprint of the key alongside the committing sequence. The slot is shared by every key that hashes to it, so a committer that finds it already holding a sequence past the version it read checks the stored fingerprint — a match is a genuine same-key conflict and the committer aborts having written nothing, while a mismatch is an unrelated key colliding into the same slot and is ignored, unless that colliding sequence is recent enough that another writer of the other key could still depend on the slot, where it stays conservative. The compare-and-swap lets exactly one of two racing same-key committers take the slot, and the decision needs only the slot and the oldest live snapshot, never another committer’s data. The reservation validates each write against the version the transaction actually read, not merely its snapshot start — so Snapshot does record its point reads, purely for that check — which closes the window where a writer becomes visible between the read and the commit. It does no read-write conflict detection, and it deliberately allows write skew — two transactions reading overlapping data and writing disjoint keys — because that matches the textbook definition, under which snapshot isolation requires only write-write conflict detection.
Serializable adds read-write conflict tracking on top of snapshot isolation, implementing serializable snapshot isolation (SSI). Repeatable Read and Serializable allocate a full read set for that tracking — Snapshot keeps only the lighter record of its point reads described above — and once a read set passes 64 entries it is backed by an xxHash table for O(1) conflict checks. At commit the engine examines other concurrent serializable transactions: if transaction T read a key that another transaction T′ wrote, it marks an outgoing conflict on T and an incoming conflict on T′. A transaction carrying both an incoming and an outgoing conflict is a pivot in a “dangerous structure,” and its commit aborts. This is a deliberately simplified SSI: it detects pivots but builds no precedence graph and does no cycle detection, so it can occasionally abort a transaction that was in fact serializable.
Transactions Across Column Families
A single transaction can span several column families, and TidesDB makes that atomic without the cost of two-phase commit. The transaction holds an array of every column family it touched, and at commit it stamps the operations in all of them with the same sequence number drawn once from the global counter. That shared number is the entire coordination mechanism: each column family’s WAL records its own operations under it, and because visibility is decided by sequence number, the writes across all the column families become visible together, in one atomic step.
The Write Path
We can now follow a write from the application all the way to durable storage (Figure 4). The path has three parts: committing the transaction into the active memtable, flushing a full memtable to an SSTable, and the flow control that keeps writes from outrunning the flushers.
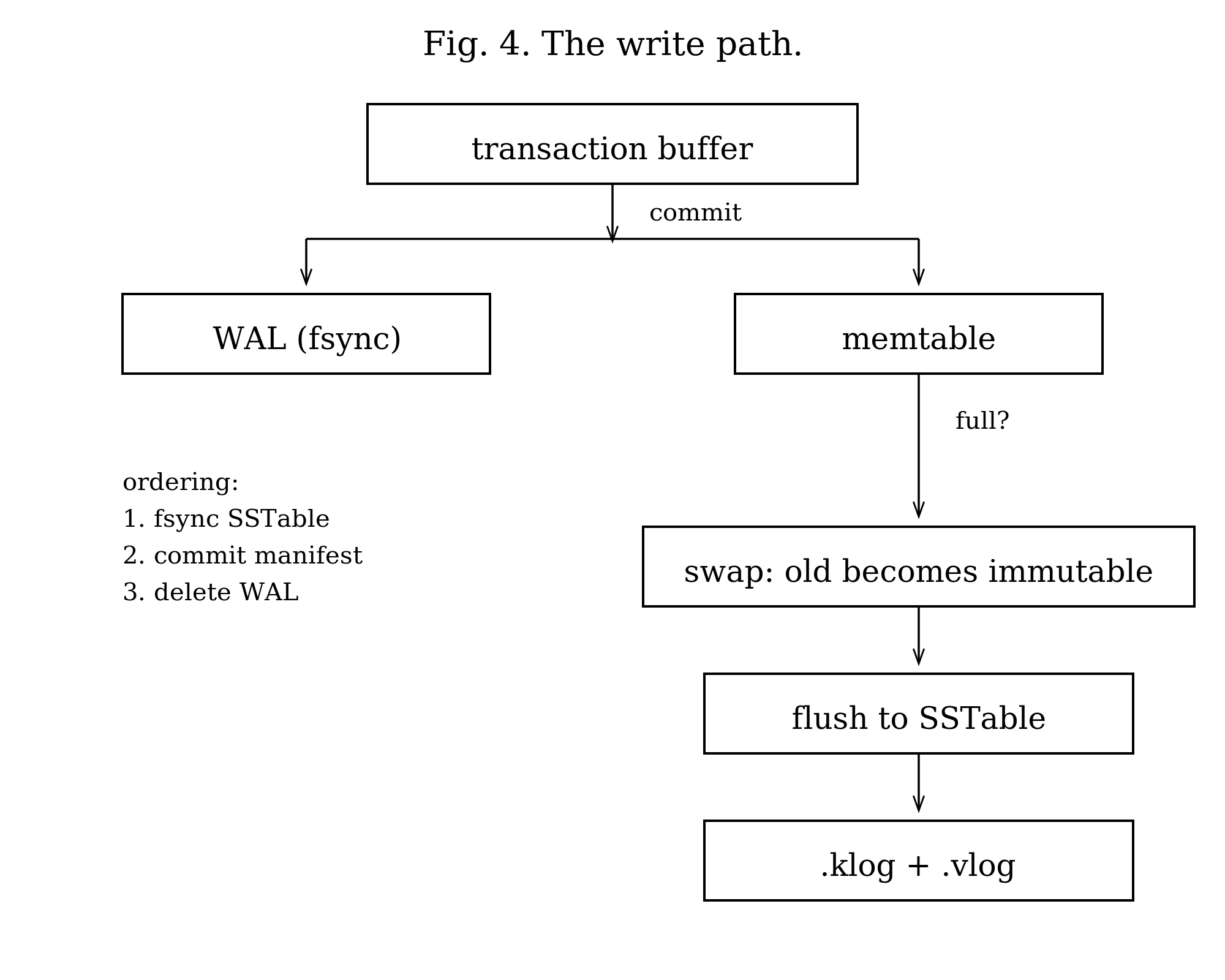
Commit
A transaction buffers its operations in memory and does nothing durable until commit. At commit the engine validates according to the isolation level, draws a commit sequence number from the global counter, reserves its write keys for first-committer-wins (Snapshot Isolation and above), writes the operations to each column family’s WAL, applies them to the active memtable under that sequence, checks whether any memtable has grown past its flush threshold, and finally marks the sequence committed — which is the step that makes its writes visible to other readers.
For Snapshot Isolation and above, validation must check each key in the write set for conflicts against the active memtable, the immutable memtables, and the SSTables at every level. Done naively this would be expensive, so two optimizations cut the cost. The first skips whole SSTables: any SSTable whose maximum sequence number predates the transaction’s snapshot cannot possibly contain a conflicting version, so it is skipped entirely — no bloom check, no block read. In a typical workload most SSTables are older than any live transaction, which removes the bulk of the conflict-detection I/O. The second optimization makes the remaining probes cheap: when an SSTable must be checked, the search runs in a sequence-only mode that finds the key through the bloom filter and block index but returns just its sequence number, allocating nothing and never touching the value log.
That scan, however, sees only writers that have already applied to the memtable, so two transactions committing the same key concurrently could each pass it without seeing the other. The reservation closes that race: drawn between the sequence number and the WAL write, each write key claims its slot — stamped with a fingerprint of the key, so a hash collision with an unrelated key is told apart from a real conflict — before anything is written, so a racing committer sees the claim and exactly one of them wins. The reservation table lives only in memory and is empty after recovery, so it changes nothing on disk, and because the loser aborts before its WAL write, an aborted transaction still leaves no trace.
A transaction also collapses its own redundant writes, keeping only the final operation per key. The deduplication table is built lazily, only once a transaction accumulates eight operations within a single column family, and uses a fast non-cryptographic hash; a hash collision simply writes both operations (the memtable handles duplicates correctly), so collisions are harmless. This shrinks the memtable when a transaction rewrites the same key many times.
Flushing a Memtable
When a memtable crosses its flush threshold, the engine hands the old one to a flush worker and swaps in a fresh empty memtable: it enqueues the frozen memtable, publishes the updated immutable snapshot, and then republishes the active pointer with a single atomic store and a memory fence for visibility. The worker then walks the frozen memtable in sorted order and builds an SSTable: it writes entries into 64KB blocks, sends large values to the value log, optionally compresses each block, and appends the block index, bloom filter, and metadata.
The threshold itself is not fixed. It adapts to how far behind the flushers are, trading write batching against memory pressure. When the flush queue is empty the threshold rises to 150% of the configured write-buffer size, letting the memtable accumulate more before flushing, which batches better and helps throughput. Under moderate pressure it falls to 125%. Once the queue is half-full or global memory is tight it drops to exactly the write-buffer size, with no slack, forcing an immediate flush. With the default 64MB buffer the effective threshold ranges from 64MB under pressure to 96MB when idle.
The final steps of a flush run in a specific order, and the order is load-bearing: fsync both files, add the SSTable to level 1, commit the manifest, then delete the WAL. Fsync before the manifest commit ensures the SSTable is durable before it becomes discoverable. The manifest commit before the WAL deletion ensures that if the machine dies in between, recovery can still find the data in the WAL.
That ordering produces exactly two crash windows, both benign. A crash after the fsync but before the manifest commit leaves an SSTable on disk that the manifest does not mention; recovery sees it is unreferenced and deletes it. A crash after the manifest commit but before the WAL is deleted leaves both the committed SSTable and the WAL; recovery replays the WAL again and produces a second SSTable, with a new ID, holding the same data. The duplicate is harmless, because every version carries its original commit sequence — reads still return the correct newest version, and a later compaction merges the copies away.
WAL files and SSTables are validated differently on read, for the same reason the flush order exists. A WAL is validated permissively: if its last block is torn or incomplete, the engine walks back to the last intact block and truncates there, because a crash mid-write is a normal thing for a log to suffer. An SSTable is validated strictly: any corruption in its last block rejects the whole table, because an SSTable is permanent and the manifest already promised it was complete.
Unified Memtable
The default arrangement gives each column family its own memtable and WAL, which means a transaction touching N column families performs N separate WAL writes. For some workloads that is wasteful. Consider a database plugin that models one logical table as a data column family plus several secondary-index column families: every transaction touches all of them, and WAL I/O grows linearly with the number of indexes.
Unified memtable mode removes that multiplier. All column families share one memtable and one WAL at the database level, so a transaction writes its WAL once regardless of how many column families it spans. It is enabled with unified_memtable = 1, and companion settings tune the shared buffer size, skip-list parameters, and WAL sync behavior.
The obvious difficulty is keeping column families from seeing each other’s keys in a shared structure. The solution is to prefix every key. Each column family gets a unique 4-byte index at creation, and every key in the shared memtable is stored with that index, big-endian, in front of the user key. The prefix does two jobs at once. It groups each column family’s keys into a contiguous sorted range (all of family 0, then all of family 1, and so on), and it makes every lookup an exact match on the prefixed key, so other families’ keys are simply never seen. Because the shared structure has one sort order, all families in it must use the default byte-wise comparator; a custom comparator is rejected at creation. Byte-wise ordering sorts the big-endian prefix numerically and then the user keys in byte order, which is exactly what is wanted.
That 4-byte index has to survive restarts, and the consequence of getting it wrong is severe: if a column family’s index changed between runs, the entire WAL would replay under the wrong families — silent data loss, not a crash. So the name-to-index map is persisted in a file (UNIMAP) at the database root, rewritten atomically whenever it changes, and keyed on column family name. Name is the only identity that outlives a crash; directory order, manifest order, and the atomic counter all reset, but the name written into the config does not. UNIMAP is loaded before any WAL is replayed, so each family re-registers under the same index it held before, the counter is advanced past the maximum loaded index so new families never collide, and in object-store mode the file is uploaded with the manifest so a cold replica reconstructs the primary’s indexes rather than inventing its own.
The rest of unified mode follows from the prefix.
Writing serializes all of a transaction’s operations, across all its column families, into one WAL batch and applies them to the shared memtable with their prefixed keys — one WAL write where per-CF mode would have done several.
Reading a key from a given family builds the prefixed key and searches the shared active memtable, then the shared immutable memtables newest-first, then falls back to that family’s own SSTable levels. Immutable memtables already flushed are skipped via a flag, so a lookup never returns data that is already durable in an SSTable.
Flushing is where the shared structure has to fan back out into per-family SSTables, and it is done in two phases so the work parallelizes. Phase one is a single cheap pass over the frozen memtable: because keys are sorted by family index first, each family’s entries form one contiguous run, and the pass simply records, for each family, how many entries its run holds. Phase two dispatches one flush task per run onto the shared worker queue. Any worker can pick up any task; each task streams its family’s run straight into an SSTable at that family’s level 1, stripping the 4-byte prefix as it writes. There is no intermediate copy, because the run is already in the family’s sort order. The task that finishes last closes the WAL segment, optionally uploads it, and marks the memtable flushed. With N non-empty families and M workers, the per-family writes run in about N/M waves instead of N. If a task’s allocation fails the dispatcher writes that run inline so nothing is lost, and a failure in one task is recorded and logged while its siblings keep going.
Rotating the shared memtable mirrors the per-CF case but must be airtight, because one memtable now backs the whole database. A compare-and-swap admission gate lets only one thread rotate at a time. Three invariants make the handoff safe: the public flush entry point takes that gate before rotating, so two racing callers cannot rotate twice and enqueue the same memtable twice; a writer captures the active pointer, takes a reference, then rechecks that the pointer is still active and retries on the new memtable if a rotation slipped in, so it can never write into a memtable that has already been frozen; and the flush worker waits for the writer reference count to drain before closing the WAL, so an in-flight write always finishes before the file descriptor it is using is torn down.
Two smaller points complete the picture. Backpressure is still applied per column family even though the memtable is shared, so a single family that is falling behind on flush or compaction still throttles its own writes. And each unified WAL has a strict one-to-one relationship with the immutable memtable it backs — no reference counting — so once a flush has demuxed all entries into SSTables, the WAL segment is uploaded if replication is on and then deleted.
Backpressure and Flow Control
When writes arrive faster than the flush workers can drain memtables, frozen memtables pile up and, without intervention, memory grows without bound. TidesDB applies graduated backpressure rather than a single on/off stall, and that gradualness is most of why its write throughput degrades smoothly under load instead of collapsing.
Backpressure watches three signals: the depth of the flush queue (call it L0; default stall threshold 10), the number of SSTables at level 1 (default trigger 4), and the size of the active memtable. Based on the pressure these indicate, it adds a small delay to each commit, applied once per column family. At moderate pressure — half the stall threshold, or three times the L1 trigger — it inserts a 0.5ms sleep, barely noticeable but enough to hand the flushers some CPU. At high pressure — 80% of the stall threshold, or four times the L1 trigger — it inserts 2ms; the jump is deliberately non-linear, taking a sharper bite out of throughput so flush and compaction can catch up. At the stall threshold and above, writes block entirely until the queue drains.
The stall is progress-based, not a fixed timeout, and this distinction is the heart of the design. A blocked writer keeps waiting as long as the flush engine is making headway, which the engine detects two ways: the L0 queue shrinking, or a global flush heartbeat advancing (flush workers bump the heartbeat as they iterate, and the dispatcher bumps it as it picks up work). So a flush that is merely slow — a big memtable on slow disk, or many column families contending for the pool — paces the writer rather than failing it. Only after a sustained run of polls in which neither signal moves does the engine conclude the flush path is genuinely wedged and return TDB_ERR_BUSY, a transient “overloaded, retry” error kept distinct from TDB_ERR_IO for a real I/O failure. A true wedge of this kind usually means a full disk, a failing disk, or a deadlock; because the error is transient, a caller can simply retry. The engine polls every 10ms, trading a little responsiveness for low syscall overhead.
The L0 stall bounds the queue of frozen memtables, but not the active memtable that writers are still filling. With many writers, if rotation is deferred because the concurrency limit on in-flight flushes is saturated, the active memtable can balloon past its buffer size before anything stops it. A hard ceiling closes that gap: at twice the write-buffer size, a committing writer stalls with the same progress-based logic as the L0 stall, kicking rotation on the way in so a deferred rotate runs the moment a slot frees. The same branch handles unified mode through the same rotation path, rather than introducing a second rotator.
Level 1 is watched alongside L0 because a high L1 count means compaction is falling behind, and a compaction backlog eventually starves flushing too (flushers wait on compaction to free space). Throttling on L1 therefore acts as a leading indicator, applying pressure before L0 becomes critical and heading off a cascade.
The per-column-family signals above cannot, by themselves, prevent an out-of-memory condition when many column families fill up at once. So a separate global guard runs in the reaper thread every 100ms. It sums all the memory the database is using — active and immutable memtables, in-flight transaction buffers, compaction scratch space, bloom filters, block indexes, and caches — and divides by a resolved limit (max_memory_usage, default 75% of system RAM, never less than 5%). The resulting pressure level is graduated by fraction of that limit: normal below 60%, elevated from 60%, high from 75%, and critical from 95%. The write path reads this level with one atomic load per commit, so it costs nothing at normal pressure. As pressure climbs, the response escalates: at elevated, the flush threshold tightens and the current family is flushed proactively; at high, the current family is force-flushed, the reaper force-flushes the largest non-flushing family, and it aggressively compacts the family with the most SSTables; at critical, writes block entirely until the reaper brings pressure down (timing out after 10 seconds with TDB_ERR_BUSY), while the reaper force-flushes every non-flushing family. In unified mode, where one memtable is shared, the reaper rotates that single memtable instead of iterating empty per-CF ones. As a last line of defense, an OS-level check polls real free memory every few seconds and forces the level to critical if free RAM drops below 5%, catching consumption that TidesDB’s own accounting cannot see.
The point of the whole scheme is smooth degradation. Increasing the write-buffer size trades flush frequency against memory used during stalls; raising the stall threshold trades memory for burst tolerance; adding flush workers drains the queue faster; and max_memory_usage caps the whole envelope. The right settings depend on the write pattern, the available memory, and the disk — but in every case the system slows down gradually as it approaches its limits, rather than swinging between full speed and a dead stop.
The Read Path
A read has to find the newest version of a key that is visible to its snapshot, and that key could be anywhere in the lifecycle — in the active memtable, in a frozen one, or in an SSTable at any level. The read path is the discipline that searches those places in the right order and makes each step cheap.
Search Order
The search runs from newest data to oldest (Figure 5): the active memtable first, then the immutable memtables newest to oldest, then SSTables in level 1, then level 2, and so on. It stops at the first match. Because newer data always sits earlier in this order, the first match is the newest version, which is exactly what a reader wants.
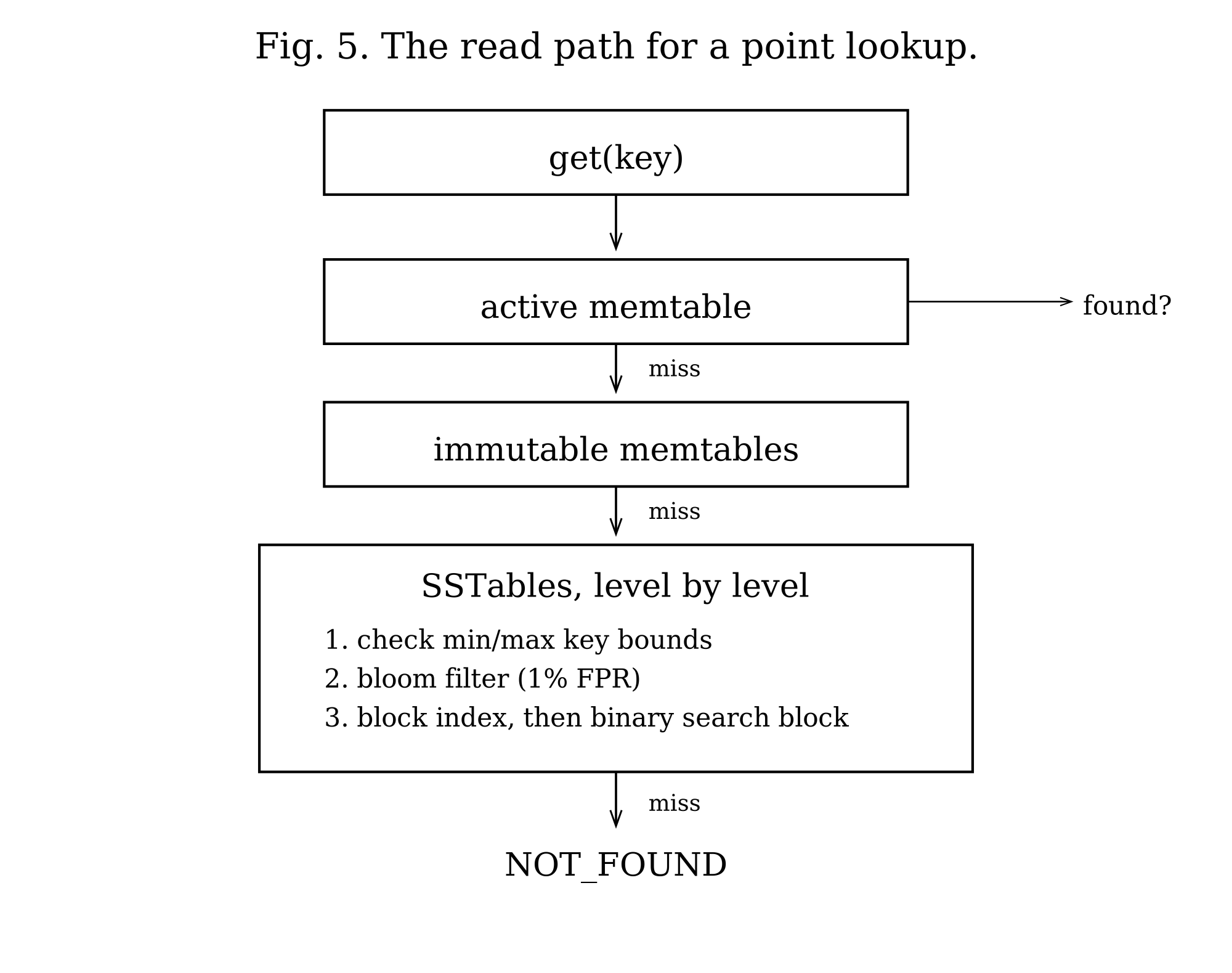
Looking Inside an SSTable
For each SSTable the search considers, the work is layered cheapest-first. It first checks the key against the table’s minimum and maximum bounds. If a bloom filter is present, it checks that next — a negative answer means the key is definitely absent, and the entire table is skipped with no I/O. If a block index is present, it identifies which block could hold the key, and the search opens a cursor there rather than at the start.
For the candidate block, the engine consults the block cache. On a hit it pins the cached block and reads directly from it, with no copy and no decompression, because the cache holds blocks already decompressed. On a miss it reads the block from disk, decompresses it, caches it, and then reads. Either way it binary-searches the block for the key, and if the matching entry points into the value log, it fetches the value from there.
One subtlety makes the block search more than a single comparison. A key can have more than one retained version in the same block, because the reader-retention floor from the previous section may be keeping an old version alive past a newer write. So the search cannot stop at the first match: it finds the key, then scans the short run of entries that share it, and returns the one with the highest sequence number at or below a ceiling supplied by the caller. A snapshot reader passes its snapshot sequence and gets the version it is entitled to; conflict detection passes the maximum value and gets the newest committed version regardless of what readers are pinning. This is what gives a precise answer for a key that holds, say, a put at sequence 5 and a delete at sequence 9 in the same block.
The bloom filter and block index are optional, per-column-family optimizations, and they are worth understanding together because a bloom false positive is what makes them matter. A false positive costs a bloom check, a block-index lookup that is probably a cache miss and therefore a disk read, a block read and decompress that is probably a second miss and a second disk read, and a binary search — roughly two disk reads spent looking for a key that does not exist. At the default 1% false-positive rate and a high query volume, that adds up, which is why the rate is tunable.
The block cache evicts with a CLOCK policy. Each entry carries a reference bit; the clock hand evicts an entry whose bit is clear and clears the bit of an entry it finds set, giving that entry a second chance. Readers set the bit on access, which both records recent use and protects an entry from eviction while it is in use, and multiple readers share a cached block without copying it.
The Block Index
The block index turns a linear scan of an SSTable’s blocks into a binary search. It stores, for each indexed block, the first and last key of that block (as fixed-length prefixes) and the block’s position in the file. The sampling ratio is configurable and defaults to every block: indexing every block costs the most memory and gives the most precision, while indexing every tenth block saves memory at the cost of occasionally scanning a few blocks per lookup.
The index is lossy, because it keeps only a prefix of each boundary key, and the lookup is built around that lossiness. Two keys with the same prefix but different suffixes can land in different blocks the index cannot tell apart, so a naive “rightmost block whose start is at or below the search key” would sometimes overshoot the block that actually holds the key. The lookup is therefore done in two steps. The first binary-searches for the leftmost block whose end-prefix is at or above the search prefix — the first block that could hold the key or one sorting after it, so the search never begins past the target. The second counts how many consecutive blocks from there share a start-prefix at or below the search prefix; that run of prefix-colliding blocks must be scanned in full before declaring the key absent, since the index cannot say which of them holds it. For unique prefixes the run is one block and the lookup reads exactly one. For shared prefixes it is short, rarely more than two or three, and still far cheaper than scanning every block. When the index covers every block, the scan is also conclusive: if the key is not in the colliding run, it is not in the table, and the search stops early.
That early stop is valuable on its own. Once the index points at a block, a key absent from that block cannot exist in a later one, because the blocks are sorted — so a negative lookup ends immediately instead of scanning to the end of the table. The same index drives iterator seeks: a seek finds the candidate block and colliding run, jumps the cursor there, and scans forward (or backward, for a reverse seek). Without it, seeking into the middle of a large table would mean scanning every block from the beginning; with it, a seek is logarithmic in the index plus a short linear scan.
One invariant matters when compression is on. The cursor advances by the on-disk (compressed) size of the block it just read, so the cached size must always be the compressed size, never the decompressed one. On a cache miss the iterator records the on-disk size; on a cache hit, where the cached bytes are already decompressed, it instead invalidates the cached size so the next advance re-reads it from the size header on disk. Writing the decompressed size back would advance the cursor into the middle of the next block — precisely the failure the block manager’s size guard exists to catch.
Iterator Fast Paths
Iteration and repeated seeks are common enough that several specific costs on their hot path have been engineered away. Each optimization targets one.
Block reuse handles seeks that stay nearby. When an SSTable source already holds a deserialized block and the seek target falls within that block’s key range, the seek searches the block in place, skipping the release, cache lookup, and deserialization cycle entirely. It handles targets before the current block (return its first entry) and after it (advance to the next block without re-running the index search). For workloads with high seek locality this drops deserialization from dominating the CPU profile to a small fraction of it, and the sequential-advance case is what makes ordinary forward iteration fast, since the next key is usually in the next block.
Boundary prefetch hides cross-block I/O. When the iterator reaches the last entry of a block, it issues an OS readahead hint on the next block, so the kernel begins loading it before the iterator asks.
Cache-aware advance closes a gap where seeks consulted the block cache but sequential advance did not. Now the advance checks the cache first; a hit pins the data with no I/O, a miss reads from disk and populates the cache. Because point lookups and iterators share the cache, one thread’s reads warm blocks that another thread’s scan then gets for free.
Incremental indexed advance avoids re-deserializing a whole block to read one entry. When a cached block carries a pre-built offset index, each step parses only the single next entry directly from the raw bytes, with key and value pointers referencing the pinned buffer with no copy. Only non-indexed blocks fall back to full deserialization.
Cached sources and zero-copy merge eliminate per-seek allocation. The iterator caches its memtable sources at creation rather than rebuilding them on every seek, pinning the active memtable with a reference so a concurrent rotation cannot free it mid-setup, and snapshotting the immutables through the same lock-free mechanism. SSTable sources expose their current entry as a borrowed pointer into pinned block data instead of allocating a fresh pair each step. Together these make the hot seek path perform zero allocations. The borrowed pointers stay valid because the iterator pins its sources for its whole lifetime; they are only copied into a stable buffer when the caller actually keeps the entry, so entries discarded while skipping over tombstones cost nothing.
Compaction
Compaction is the process that keeps the LSM tree healthy. Flushing alone would pile up an ever-growing number of SSTables at level 1, and read amplification would climb without bound. Compaction merges SSTables together, discards data that has been superseded or deleted, and moves data down into the level hierarchy so that each level stays within its size budget. It is, in effect, the engine paying down the write- and read-amplification debt it took on by writing fast in the first place.
How Compaction Decides What to Do
TidesDB does not expose the usual menu of named policies (leveled, tiered, and so on). Instead it runs three merge strategies and chooses among them automatically from the current shape of the tree, following the principles of the “Spooky” compaction algorithm and working alongside a second mechanism, Dynamic Capacity Adaptation, described below. A single controller drives the whole process.
Compaction fires under any of three conditions. The first is file count: when level 1 accumulates a threshold number of SSTables (default 4), flushed memtables are piling up and must be merged downward. The second is level capacity: when level 1’s total size exceeds its budget, data must move down to preserve the rule that each level is roughly N times the one above it. The fire condition watches level 1 specifically; once a compaction runs, the dividing-level logic below decides how far down the tree to rebalance, so a deeper level over its budget is resolved by the merge that gets scheduled rather than by firing a trigger of its own. The third is tombstone density, which deserves its own explanation.
A deletion in an LSM tree is not an erasure; it is a tombstone, a marker that shadows older copies of the key in deeper levels. A tombstone can only be physically dropped once it reaches the largest level, where there is nothing beneath it left to shadow. Until then, every range scan over a deleted region pays to skip past the accumulated tombstones. A delete-heavy column family that rarely triggers a structural compaction can therefore build up enough tombstones to badly hurt scan latency. The density trigger watches for this. Each SSTable records its tombstone count next to its entry count, persisted behind a flag bit so older binaries stay compatible. After each flush, a witness pass asks whether any single SSTable’s ratio of tombstones to entries exceeds a configured trigger while holding at least a minimum number of entries (so a tiny all-tombstone table does not fire it). One dense table is enough; on a hit, the engine steers a compaction toward the largest level, where the tombstones can finally be reclaimed. The trigger is off by default (ratio 0.0) and arms when set above zero, and it runs independently of the structural triggers, so a workload that never trips file-count or capacity can still get tombstone relief. The same witness is wired into both per-CF and unified flushes, and the engine exposes the underlying counts (total tombstones, per-level breakdown, worst single table) so operators can see how close they are to the trigger and tune it.
The Dividing Level
When compaction does run, it first computes a dividing level, written X, which is its primary target (Figure 6). X is a real level in the tree, not an abstract reference point:
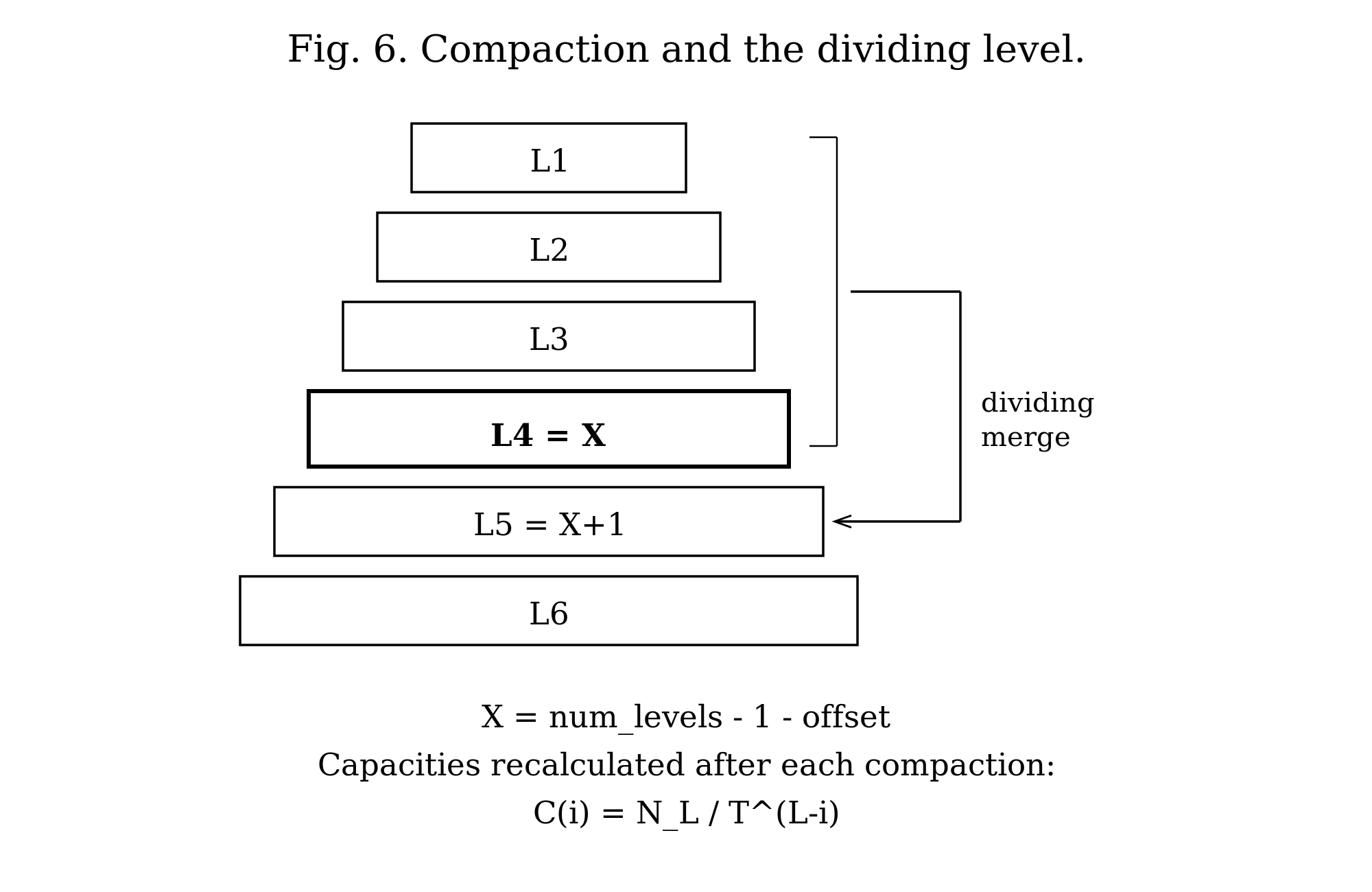
X = num_levels - 1 - dividing_level_offsetThe offset (default 1) tunes aggressiveness: a smaller offset compacts more often into deeper levels, a larger one defers the work. With 7 active levels and the default offset, X is 5, so level 5 is the primary merge destination. Given X and the level that triggered the compaction, the engine picks one of three strategies. If the triggering level is X, it runs a dividing merge, consolidating levels 1 through X back into X — the common case under steady writes. If some level shallower than X can absorb the combined data of levels 1 through itself, it runs a full preemptive merge into that level, handling intermediate levels that fill faster than expected. And if X is still over capacity after the initial merge, it runs a partitioned merge as a secondary cleanup.
The Three Merge Modes
Each mode suits a different point in the tree’s life.
The full preemptive merge is the simplest: it combines all SSTables across a range of adjacent levels into the target level. It opens every source, builds a min-heap of them, and repeatedly emits the smallest surviving key, keeping only the newest version of each, dropping expired entries, and dropping tombstones only when the target is the largest level and the merge reaches it from the top. It is effective for small merges but, because it does not partition the key space, it can produce large output files. It also serves as the fallback for the other two modes when they cannot work out partition boundaries.
The dividing merge is the workhorse of steady-state writes, taken when the target equals X. It consolidates levels 1 through X and writes the result back into X. If X is already the largest level, the engine first adds a new level beneath it so the tree always has room to grow downward. Crucially, it partitions intelligently: it reads the key ranges of the SSTables one level below and uses them as boundaries, merging in chunks so that each output SSTable covers a single range and is pre-aligned with the level it will later be pushed into. This keeps output files small and evenly spread across X instead of producing one monolith. If no boundaries can be found — the level below is empty — it falls back to a full preemptive merge.
The partitioned merge is a focused secondary cleanup, used when X is still over capacity after the initial merge. Rather than merging from level 1, it works on a narrow range starting at X, again using the largest level’s key ranges as partition boundaries and producing small single-range outputs. It relieves pressure in one part of the tree without triggering a tree-wide compaction, which keeps compaction from falling behind during bursty writes. When it targets the largest level, its output files are capped at the dividing level’s capacity (per Algorithm 2 of the Spooky paper), splitting at block boundaries if a partition would exceed that. This bounds transient space amplification regardless of how skewed the partition’s keys are.
Running Merges in Parallel
A compaction round is serialized per column family, to preserve level invariants and manifest ordering, but the work inside a round is not single-threaded. All three modes split their output into independent key-range partitions and run those partitions concurrently. An executor is handed N partitions and borrows up to N−1 helper threads from a database-wide budget, with the calling worker pitching in as well. Because the budget is shared across all column families, several rounds on different families can never oversubscribe the pool. Partitions are claimed through an atomic work-stealing cursor — each worker grabs the next one and repeats until they run out — and because the calling thread always works, progress is guaranteed even if the budget is zero or a thread fails to spawn; unclaimed partitions are simply picked up by whoever is free. Each partition owns its merge heap and output and writes independently; only the commit step (adding the output to its level and committing the manifest) is serialized, on a per-family lock. The three modes differ only in how they derive the partition boundaries — sampled from input keys for the full preemptive merge, taken from the level below for the other two — and when no boundaries exist, the merge runs as a single partition on the calling thread, exactly the old serial behavior.
Inside a Merge
All three modes share one execution path. It opens every source SSTable across the level range, builds a min-heap ordered by current key under the column family’s comparator, and repeatedly pops the smallest source, advances its cursor, and sifts it back in under its new key.
Filtering happens as entries are popped. When several sources hold the same key, only the highest sequence survives — unless an older version sits at or above the reader-retention floor, in which case it is kept because a live snapshot may still need it. Expired entries are dropped. A tombstone is dropped only when the merge both writes into the largest level and started at the top of the tree, so that nothing beneath it remains to shadow and no shallower level is left holding an older put that could resurface — a partial merge into the largest level from a middle level keeps the tombstone. Even then the drop waits until the tombstone’s own sequence has fallen to or below the reader-retention floor and below the oldest write still unflushed in a memtable, so neither a long-running reader nor a not-yet-flushed older version can watch the deleted key reappear. Merging into a shallower level keeps the tombstone so it goes on shadowing deeper versions. Survivors are written into 64KB blocks with large values going to the value log, blocks optionally compressed, followed by the block index, bloom filter, and metadata, and both files are fsynced.
The commit order protects concurrent readers, mirroring the flush rule. The merged output is added to its target level before any input is removed, so a reader always sees at least one copy of every key. The manifest commit is atomic — temp file, fsync, rename. The inputs are then removed from the in-memory levels in a single atomic swap per level, processed deepest level first; because a point read stops at the first level holding the key, removing deepest-first guarantees a reader sees either all of a level’s merged inputs or none, never an old put stranded without the tombstone that shadowed it. The actual file deletions can be deferred to the reaper so they never block the worker.
Skipping tombstones efficiently is its own small art. The merge heap only copies a popped entry into the iterator’s buffer when the caller actually keeps it, so tombstones discarded during a skip cost nothing. The skip loop — shared between forward and backward iteration — copies the tombstone’s key to a stable stack buffer and then advances every other source whose current entry matches, each at the cost of one cursor step and no copies. The key is copied to the stack first precisely so that later pops inside the loop cannot overwrite the pointer the comparator still depends on.
If a source hits corruption while advancing, the heap catches it through a checksum failure, hands the bad SSTable back to be deleted, drops it from the heap, and finishes the merge with the rest — so one damaged table cannot stop compaction. And large values flow through the merge rather than being copied verbatim: each is read from the source value log, recompressed under the current configuration, and written to the destination, which lets compression settings change over time without a full rebuild.
Single-Delete: Dropping Tombstones Early
The tombstone rule above is conservative for a reason, but the conservatism has a cost worth optimizing away in a specific case. A regular delete must be carried through every compaction until the largest level, because some deeper level might still hold an older put it needs to shadow. Workloads that put a key once and delete it once therefore pay a read tax until a bottom-level compaction finally reaps the tombstone.
tidesdb_txn_single_delete lets a caller opt out of that conservatism, under a contract: between any two single-deletes of a key (and before the first), the key was put at most once. Under that promise the engine may drop a put and its matching single-delete together the first time a merge sees both, at any level. Reads treat a single-delete like any other tombstone; the difference lives entirely in the merge. The subtype is a second flag bit carried beside the tombstone bit, already part of the persisted byte, so the format is unchanged and older binaries simply see a tombstone. The bit rides the whole write path — WAL, skip list, flush, merge sources — into compaction.
The cancellation happens during the merge’s emit phase. Because the heap delivers a key’s versions newest-first, the first entry popped for a key is the newest survivor; the emit loop holds it pending and resolves it when the next distinct key arrives. If that pending entry is a single-delete and the next older version of the same key is a live put, the pair is cancelled: the single-delete is dropped outright and the put with it. A pending regular tombstone that found no pair follows the ordinary rules. The same lookahead runs at every emit site, with the partitioned merge using a slightly narrower peek variant to fit around its mid-loop file splitting; the effect is identical for the dominant case where put and single-delete arrive adjacent. Violating the contract — putting a key more than once between single-deletes — cannot be detected by the engine; the result is that only the most recent put is masked while older puts stay visible, so a caller who cannot guarantee the contract must use a regular delete.
Compacting a Range on Demand
The density trigger reclaims space automatically, but operators sometimes need to reclaim a known key range now — after a large range delete, on tenant eviction, or for a sliding-window expiry that does not fit TTL. tidesdb_compact_range does this synchronously: it snapshots each level, selects only the SSTables overlapping the range, and merges them on the calling thread, leaving everything outside the range untouched. It runs inline rather than queuing, so if a background compaction is already in flight on the family it returns TDB_ERR_LOCKED at once rather than waiting behind it. The merge uses the same emit logic as the automatic ones — tombstone reclamation, single-delete cancellation, deduplication, recompression — so the output matches what a background compaction would have produced. It shares the heap, block writer, and manifest machinery with the other modes and blocks until it commits or fails. The witness-driven path from the density trigger is the asynchronous sibling of this call: it enqueues a steer-to-bottom work item instead of running inline, but applies the same rules. Together they capture most of the value of a true range-tombstone primitive without its cost: a range delete still writes per-key tombstones, but the operator can reclaim the affected tables in one pass immediately afterward. The plain tidesdb_compact call similarly blocks until its work item has been serviced, but enqueues onto the global queue rather than running inline, so calls from different threads can run in parallel across column families; it is never coalesced against an in-flight compaction, so each call captures everything committed up to the moment it was made.
Dynamic Capacity Adaptation
The three merge modes decide how to merge. Dynamic Capacity Adaptation (DCA) is a separate mechanism that decides when to add or remove levels and continuously retunes each level’s capacity to match the data that actually exists. It does not run continuously; it fires after events that change the tree’s shape — at the end of a compaction cycle, and after a level is removed.
Its core is a recalculation of every level’s capacity from the measured size of the largest level:
C_i = N_L / T^(L-i)Here C_i is the new capacity for level i, N_L is the actual byte size of the largest level L (the ground truth of how much data exists), T is the level-size ratio (default 10), and L is the number of active levels. Anchoring capacities to the real data at the bottom of the tree is what keeps compaction timing optimal as the database grows or shrinks: it avoids both over-provisioned capacities, which raise read amplification, and under-provisioned ones, which cause excessive compaction and write amplification.
DCA adds a level when a dividing merge needs to write below the current largest level, or when a level overflows and needs a destination that does not yet exist. It creates the empty level, increments the active count, and lets ordinary compaction move data into it — no data is migrated during the addition itself, which avoids a whole class of key-loss bugs. It removes a level only under strict conditions: the largest level is completely empty after a compaction, the active count is above the configured minimum, the level was not just added this cycle, and no flushes are pending. The minimum-level check prevents thrashing — adding and removing the same level repeatedly. On startup, a column family begins with at least its configured minimum number of levels, or more if recovery finds SSTables deep in the tree, and each level’s capacity is set directly from the configured base size and ratio. DCA itself does not run during open; it takes over once the tree’s shape next changes — at the end of a compaction cycle, or when a level is removed — re-deriving the capacities from the data that actually exists.
Summary
Compaction is three merge modes, chosen automatically, working with DCA to scale the tree up and down with the data. A dividing merge is the steady-state workhorse, taken when the target equals the dividing level X; a full preemptive merge handles a shallower level that fills early; a partitioned merge is the secondary cleanup when X stays full. The dividing level is a one-line formula rather than the output of any complex analysis. Tombstones are reclaimed conservatively by default and eagerly under the single-delete contract, automatically by the density witness and on demand through range compaction. The result handles everything from steady writes to sudden bursts while protecting both read and write performance through deliberate placement and scheduling.
Recovery
Recovery is the inverse of the write path: it reconstructs the in-memory state from what survived on disk, so the database resumes exactly the logical state it had before a crash. On startup the engine reads the database-root state, scans each column family’s directory, and rebuilds its structures in a careful order.
The database-root state loads first. In unified mode this means reading UNIMAP before any column family opens, so each family re-registers under the index it held before the crash and replayed WAL entries land in the right group — the ordering is load-bearing, since getting it wrong would replay the log under the wrong families. Each column family’s manifest then loads. On a normal local restart the engine recovers level membership by scanning the directory (the level is encoded in each SSTable’s filename) and uses the manifest as a completeness check, confirming each SSTable finished its commit handshake; the manifest drives membership directly only on object-store cold start, where no local files exist.
WAL replay happens in place, and that detail is what makes recovery deterministic. The engine adopts the highest-numbered WAL segment and opens it where it sits rather than discarding it, validates it permissively (trimming only a preallocation tail or torn final block), and replays every committed entry directly into the column family’s active memtable. The memtable a fresh open hands back to the application is the very one the WAL replayed into; ordinary flush pressure promotes it to an SSTable later. Older, lower-numbered segments left by a crash are replayed into separate memtables and flushed asynchronously. The unified WAL recovers the same way — adopt the highest generation, validate, replay into the shared memtable — with each entry’s prefix resolving correctly because UNIMAP already loaded.
The sequence counter is recovered to match. The engine scans the maximum sequence across the recovered SSTables, the immutable memtables, and the active memtable the WAL just filled, and advances the global counter past it. This is why a transaction that reached the WAL but never an SSTable still counts: its sequence is seen during the scan and stays visible to readers in the new run.
SSTables are validated strictly, the mirror of the WAL’s permissiveness. A log is transient and append-only and must tolerate torn tails because recovery routinely meets them; an SSTable is permanent, so the manifest is the authority on which ones finished their commit handshake. An SSTable on disk that the manifest does not list is an incomplete write — a crash after the fsync but before the manifest commit — and recovery deletes it. An SSTable the manifest does reference but that fails to load is kept on disk rather than condemned, since a load failure can come from a write-side bug as readily as from media corruption; it is skipped for this open and logged loudly, so a later repair stays possible instead of the data being lost outright.
Background Workers
The work that does not happen on the caller’s thread happens here (Figure 7). Flush and compaction workers are configurable thread pools; the sync worker and the reaper are single threads. Object-store mode adds an upload pool, and a read-only replica adds a sync thread of its own.
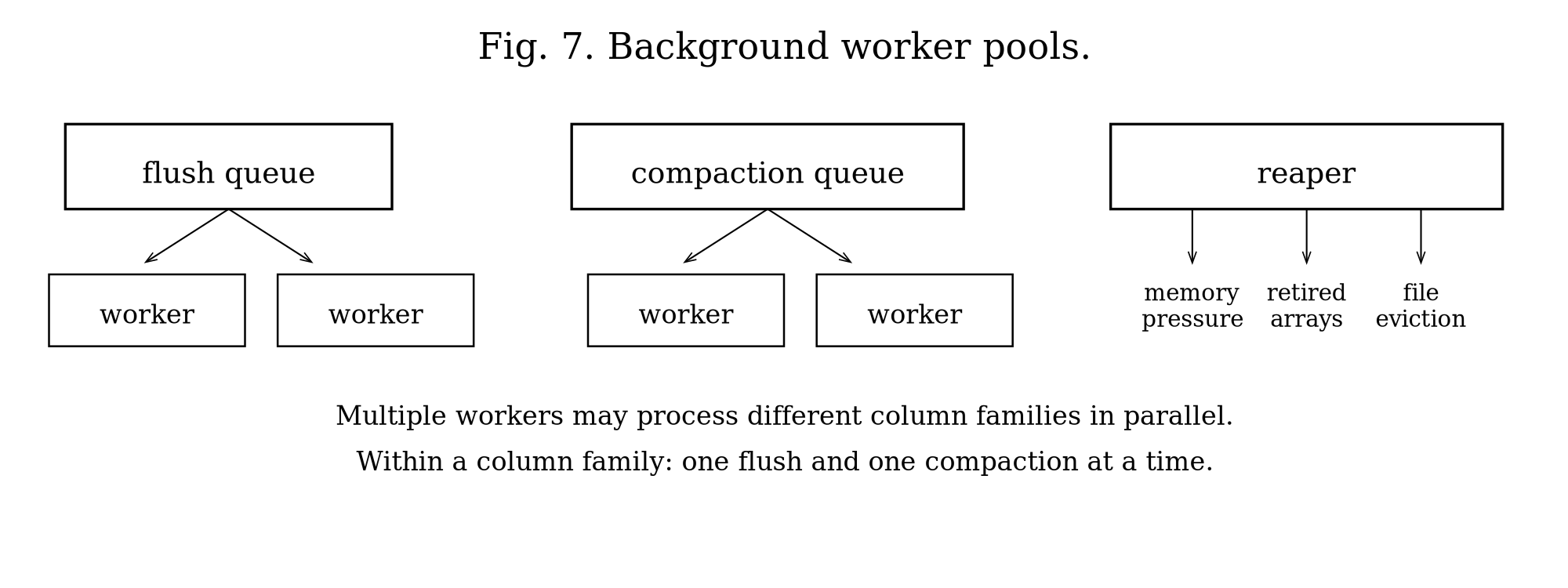
Flush workers (default auto, min of CPU count and 4) take frozen memtables off the queue and write them to SSTables, in parallel across column families. Compaction workers (default 2) merge SSTables across levels, in parallel across families, and fan out within a single round through sub-compaction. The sync worker (1 thread, started only if any WAL uses interval sync) periodically fsyncs the WALs configured for it; it finds the smallest configured interval, sleeps that long, and syncs each due WAL. Column families on interval sync also force an explicit fsync at structural boundaries — when a memtable rotates, and during every sorted-run creation and merge — which preserves durability while still batching ordinary writes.
The reaper (1 thread) runs a maintenance loop every 100ms and is the system’s general groundskeeper. Each cycle it sweeps the deferred-free list, retries flushes that were deferred under the concurrency cap, redelivers object-store uploads that exhausted their fast retries (in object-store mode), services any compaction triggers that arrived while a compaction was already running, recomputes global memory pressure and acts on it, and evicts idle SSTable file handles when too many are open. The memory-pressure response was described with Backpressure; the two pieces of bookkeeping unique to the reaper are worth a word each.
Retired-array reclamation solves a lifetime problem. When a flush or compaction swaps a level’s SSTable array, the old array cannot be freed at once, because a reader may still be walking it. Each level keeps a counter of active readers. Rather than spinning until it hits zero — which would stall the worker and cascade under mixed load — the worker spins briefly, and if readers remain, pushes the retired array onto a lock-free deferred-free list. The reaper sweeps that list each cycle, freeing what has gone quiet and re-queuing the rest, and a final drain at shutdown clears whatever is left.
File-handle eviction bounds open descriptors. Each SSTable uses two (key log and value log). When the open count reaches its budget — the configured maximum less a reserve held back for the write path — the reaper closes the least recently used quarter of the idle, unreferenced tables, reclaiming down to that budget rather than to the maximum, so the reserve stays available as burst headroom. The default maximum is 256 SSTables (512 descriptors), lower on platforms with tighter limits. If the working set is persistently larger than the budget, the reaper evicts continuously, and descriptors thrash.
How Work Is Distributed
The database keeps two global queues, one for flushes and one for compactions, each work item naming its column family. A memtable crossing its threshold enqueues a flush; a level over capacity enqueues a compaction. Workers block until work arrives, and different workers serve different families at once.
Two atomic flags coordinate per family, and a subtlety in how they are used is worth stating because it surfaces in the public API. The is_flushing flag is now only a brief gate over the memtable swap and the enqueue — it no longer means “a flush is in progress.” Concurrency on the actual SSTable writes is bounded instead by a database-wide counter capped at the flush-thread count, behaving like a semaphore; a hot family can thus have several memtables flushing at once and drain its queue at pool speed, while the global cap also bounds total transient memory across many families. Compaction rounds stay one-per-family via is_compacting to preserve invariants, with a trigger that arrives mid-round setting an “armed” flag the worker honors afterward rather than dropping. Because is_flushing is just a gate, the real “is anything being written” signal is a per-family pending-flush counter, and the completion wait polls that, so a caller asking for its data to reach disk does not get a false all-clear the instant the rotate gate clears. The public tidesdb_is_flushing and tidesdb_is_compacting check both the flag and the counter and report true if either shows pending work; operators reading these externally should read is_flushing as “a rotation is in flight” and the counter as “queued or running flushes exist.” For forced maintenance, tidesdb_purge_cf synchronously flushes and aggressively compacts one family (rotating the shared memtable first in unified mode), and tidesdb_purge does the same across all families and drains both global queues.
The parallelism that results is straightforward to reason about. Flush and compaction workers run different families in parallel; a single family can flush multiple memtables at once up to the cap, so a hot family drains at pool speed; and compaction stays serialized per family but fans out within a round. For sizing, set flush threads toward the number of concurrently hot families and compaction threads toward the number of families; with N families and M flush workers, flush latency on a quiet family is roughly (N/M) times the flush time. The main thread always enqueues and returns immediately, which is what sustains the write throughput.
Error Handling
Functions return an integer: zero for success, a negative code for a specific failure.
| Code | Value | Meaning |
|---|---|---|
TDB_ERR_MEMORY | −1 | allocation failure |
TDB_ERR_INVALID_ARGS | −2 | invalid parameters |
TDB_ERR_NOT_FOUND | −3 | key not found |
TDB_ERR_IO | −4 | I/O error |
TDB_ERR_CORRUPTION | −5 | data corruption detected |
TDB_ERR_EXISTS | −6 | resource already exists |
TDB_ERR_CONFLICT | −7 | transaction conflict |
TDB_ERR_TOO_LARGE | −8 | key or value too large |
TDB_ERR_MEMORY_LIMIT | −9 | memory limit exceeded |
TDB_ERR_INVALID_DB | −10 | invalid database handle |
TDB_ERR_UNKNOWN | −11 | unknown error |
TDB_ERR_LOCKED | −12 | database locked by another process |
TDB_ERR_READONLY | −13 | write attempted on a read-only replica |
TDB_ERR_BUSY | −14 | transient overload; a backpressure stall hit its no-progress budget (retry; matches POSIX EBUSY) |
TDB_ERR_PRECONDITION | −15 | a conditional object-store write failed its precondition (HTTP 412); raised by single-writer fencing when a superseded primary tries to publish |
More codes appear in the C reference.
The guiding distinction is between transient errors (out of disk, out of memory) and permanent ones (corruption, invalid arguments). Durability rests on fsync, every disk read is checksum-validated by the block manager, and magic numbers catch corruption at the SSTable level. A few scenarios are worth making explicit. A failed pre-flush disk-space check skips the flush and leaves the memtable in memory; a write that fails partway discards the partial SSTable and re-enqueues the work for retry — in both cases writes keep flowing into the active memtable until backpressure stalls them, and the failure is logged rather than surfaced per write. Corruption found on read returns TDB_ERR_CORRUPTION without condemning the whole SSTable, since a later read may hit an intact block; corruption found during compaction drops the bad table and continues; an allocation failure during compaction aborts it and leaves the old SSTables intact for the next attempt. One configuration error the engine cannot detect is a changed comparator between restarts: keys end up out of order, lookups miss, iterators return them wrongly, and compaction produces mis-sorted output — the logical structure is corrupted with no physical corruption at all. Bloom false positives cost two needless disk reads but raise no error.
Design Rationale
The defaults are not arbitrary; each is a trade-off struck at a particular point. This section records the reasoning, so the defaults can be moved with eyes open.
Block size trades compression efficiency against random-access granularity. Larger blocks compress better, because they give the compressor more context, but a point lookup must read a whole block to find one value; smaller blocks cut that waste but compress poorly and inflate the block index. The 64KB target matches common SSD page sizes and compresses text 2–3×.
The level-size ratio, how much larger each level is than the one above, sets write amplification: each level holds N× the previous one. A smaller ratio (5×) lowers write amplification but adds levels and hurts reads; a larger ratio (20×) removes levels but raises write amplification. Default 10×, per column family.
Write amplification follows from that ratio. In leveled compaction an entry is rewritten about once per level it passes, and the average works out to roughly R·L/2 rather than R·L because shallow levels are rewritten more often than deep ones. For a 1TB database with a 64MB level 1 and ratio 10, the tree settles at about 6 levels, so write amplification is around 30× — not the 60× a naive estimate suggests. Updates amplify less than pure inserts.
Read amplification, in the worst case, is one SSTable read per level — 6 reads at 6 levels without bloom filters. At a 1% false-positive rate, the expected reads for an absent key fall to about 1.06, since the bloom rejects almost every level with no I/O. For a key that is present, bloom filters do not help; the block still has to be read.
The value-log threshold keeps the key log compact for scanning: values at or above 512 bytes go to the value log. A smaller threshold causes many value-log seeks; a larger one bloats the key log. The default is roughly the point where the cost of the indirection becomes cheaper than scanning a large inline value during iteration.
The bloom false-positive rate, 1% by default, balances memory against effectiveness: dropping to 0.1% needs ten times the bits per key to cut false positives tenfold, while 5% saves memory at the cost of more pointless reads. At 1% a filter is about 10 bits per key, so a million keys cost roughly 1.25MB — small enough to stay resident.
Memtable size trades flush frequency against recovery time and memory. Larger memtables flush less often but lengthen recovery and use more memory; smaller ones flush more (more SSTables, more compaction) but recover faster. The 64MB default holds about a million small pairs and flushes every few seconds under moderate load. Doubling it halves flush frequency but raises level-1-to-level-2 amplification, since each flush produces a larger table that takes longer to merge.
Worker counts default to auto flush threads (the CPU count, capped at 4) and two compaction threads, which give cross-family parallelism at modest cost. More threads help with many active families but cost memory (each buffers 64KB blocks) and descriptors (two per table in flight). The device dominates the choice: on a spinning disk, several concurrent compactors cause head seeks that destroy throughput; on NVMe, more workers help. So 1–2 workers for HDD, 4–8 for NVMe.
Operational Considerations
A TidesDB instance is safe for many threads in one process but exclusive to a single process: only one process may open a database directory at a time. Exclusivity is a non-blocking file lock taken during open — if another process holds it, open returns TDB_ERR_LOCKED at once rather than waiting. The locking primitive is chosen per platform for correct semantics: fcntl locks on macOS and BSD (which, unlike flock, are not inherited across fork, with the owning PID written to the lock file so a same-process double-open is caught), OFD locks on modern Linux, and LockFileEx on Windows, with retries on signal interruption so a stray signal cannot spuriously fail the lock.
Memory use per family comes from a few structures: the active memtable is configurable (default 64MB) and the immutable queue is that size times its depth (usually 1–2); the block cache is shared across families (default 64MB total); bloom filters cost about 10 bits per key and block indexes about 32 bytes per block. A family with 10M keys across 100 SSTables therefore runs around 150MB plus its share of the cache. The max_memory_usage cap (default auto, resolving to 75% of system RAM, never clamped below 5%) bounds the aggregate across all families, which is what prevents an out-of-memory condition in many-family deployments where per-family limits cannot.
Three operational limits interact at the margins. When writes outpace compaction, backpressure stalls them once the flush queue passes its threshold, trading occasional latency spikes for bounded memory. Because SSTables are immutable, space is reclaimed only after a compaction finishes and deletes its inputs, so a compaction can briefly need double the space of the level it rewrites; the engine checks free space before starting one. And because each SSTable holds two descriptors open, a working set larger than the open-file budget makes the reaper thrash; an operator who wants a bigger resident set can raise the process’s descriptor ceiling before opening the database, after which the engine sizes its budget to fit. The raise is opt-in and a partial failure is non-fatal.
On-Disk Format
Up to here, the formats have been described by what they accomplish. This section gives the bytes. It is placed last among the engine internals on purpose: by now every structure has been seen in use, so the layouts read as the concrete realization of ideas already understood rather than as detail to memorize up front.
The Key-Log Entry
Every entry in a key log — and, since they share the format, every entry in a per-CF write-ahead log — is laid out as:
flags (1 byte)key_size (varint)value_size (varint)seq (varint)ttl (8 bytes, if HAS_TTL flag set)vlog_offset (varint, if HAS_VLOG flag set)key (key_size bytes)value (value_size bytes, if inline)The flags byte marks a tombstone (0x01), the presence of a TTL (0x02), value-log indirection (0x04), delta sequence encoding (0x08), and the single-delete tombstone subtype (0x10, always set alongside the tombstone bit). The remaining high bits are in-memory ownership bookkeeping and are masked off before any write, so they never reach disk. The integers are varints, so the common case is small: a value under 128 takes one byte, and the full 64-bit range takes at most ten.
The unified WAL uses a slightly different batch framing, since one log now carries entries for many column families: a 2-byte magic (0x55AA) opens the batch, and each entry is prefixed with its 4-byte big-endian column family index ahead of the standard fields. Recovery recognizes a unified WAL by its filename prefix and magic, replays each entry into the shared memtable with its prefix intact, and flushes it through the normal unified path.
Auxiliary Blocks and the Chunking Edge Case
The block index, bloom filter, and metadata at the tail of a key log are each written as ordinary blocks, and a single block is framed by a 4-byte size field that caps it just under 4GB. In practice this ceiling never binds: a bloom filter is bounded by its bit count, itself a 32-bit quantity, so even a bottom-level SSTable with hundreds of millions of keys serializes its bloom to under a gigabyte, and a block index is far smaller. Both fit in one block.
The format is nonetheless built to be correct at any size, not merely large enough. An auxiliary blob that would overflow the single-block limit is split across consecutive blocks instead of failing the write; the metadata records each chunked blob’s offset and total size behind a flag bit, and the reader reassembles the chunks before deserializing. A blob that fits in one block — every bloom filter and block index produced in practice — sets no flag and is laid out byte-for-byte as older binaries expect, so the format stays backward-compatible. Chunking thus stays dormant for real data and engages only for a blob that genuinely cannot fit one block, reachable only if the bloom’s bit count were ever widened past 32 bits. One footer-writing routine is shared by the flush path and every merge writer, so chunking applies uniformly. On read, the block manager never trusts a size field blindly — it rejects any size whose block would run past the file, and refuses any size beyond a memory-safety budget — and a column family that cannot load an oversized bloom simply runs without it. That size guard is detailed under Block Manager.
The Metadata Footer
The last block of a key log is its metadata footer, the table’s self-description: a magic number, the entry and block counts, the data-end offset and file sizes, the minimum and maximum keys, the maximum sequence number, the compression algorithm, a flags word, and an xxHash64 checksum over everything preceding it. Versioning lives in the flags word rather than a version integer, and it is additive — a newer build sets a flag and appends a section, while a build that does not understand the flag would reject the size, and a newer build reading an older footer that lacks the flag simply treats that section as absent. Four flags are defined: one marks the B+tree format, one an eight-byte tombstone count, one a chunked-auxiliary descriptor for a bloom or index blob too large to fit a single block, and one an eight-byte distinct-key count. The reader computes the exact expected size from the flags and refuses any footer whose size does not match, then verifies the checksum before trusting a byte, so a truncated or reordered footer never deserializes.
The tombstone count and the distinct-key count are summary statistics tallied for free during the sorted-run write and read back without a scan. The tombstone count feeds the density trigger from Compaction. The distinct-key count records how many unique keys the table holds rather than how many versioned entries — the two diverge whenever a snapshot kept older versions alive through a flush or merge — and it is counted with a single comparison against the previous key as the already-sorted run is written, so it needs no hashing and no sketch. tidesdb_cf_estimate_cardinality sums it across a column family’s tables, plus the in-memory entries, to estimate the family’s key cardinality without touching the data; because a key living in several tables is counted once per table, the estimate is an upper bound, which suits selectivity and row-count planning. A table written before either count existed reports it as unknown and the reader falls back to the entry count, so the format stays compatible in both directions.
The B+tree Format
A column family may store its key log as a B+tree rather than the default block layout, enabled with use_btree=1. All key-value entries live in the leaves; internal nodes hold only separator keys and child pointers. Leaves are doubly linked through previous- and next-offset pointers, giving O(1) traversal either way. The tree is immutable once built: it is bulk-loaded from sorted memtable data at flush and never changed.
Construction is bottom-up. The builder fills a leaf to the target node size (64KB by default), serializes it, and writes it out; once all leaves exist it builds internal levels from the first key of each child; a final backpatching pass fills in the leaf links. For compressed nodes the links live in an uncompressed header, so backpatching rewrites them without decompressing the node. A point lookup descends root to leaf, binary-searching at each internal node and again within the leaf — O(log N) in nodes, against the potential multi-block scan of the block format. Range scans use a cursor that walks a leaf’s entries and follows the link to the next (or previous) leaf.
As in a key-log block, a leaf can hold several retained versions of one key, so the leaf scan cannot stop at the first match: the lookup lower-bounds to the key, scans the contiguous run that shares it, and returns the highest sequence at or below the caller’s ceiling. The builder cooperates by keeping a key’s whole version run inside one leaf, so the scan never crosses a boundary, and the ceiling is threaded from the caller’s snapshot exactly as in the block format — a put-then-delete returns the delete to a fresh reader and the put to a snapshot that predates the delete, with no race between leaves.
The B+tree wins on point lookups and on seeking range scans, and most on workloads with many small-to-medium SSTables, where each table’s hot nodes stay cached independently; the block format remains better for sequential full-table scans and write-heavy workloads, where the B+tree’s flush-time overhead does not pay off. When a block cache is configured the B+tree gets a dedicated clock cache of fully deserialized nodes, keyed by a hash of the key-log path plus the node offset, with each node’s memory drawn from a single arena so eviction frees it in one step and an SSTable’s nodes invalidated by prefix when it closes. Large values still go to the value log with the leaf holding only the offset; nodes compress independently; bloom filters are checked before any traversal; and five extra metadata fields (root offset, first and last leaf offsets, node count, height) are persisted and restored on reopen.
Several techniques shrink each serialized node. Varint encoding of metadata fields (counts, sizes, offsets) typically saves 50–70% over fixed-width integers. Prefix compression stores each key as a shared-prefix length plus its suffix, reconstructing it from its predecessor, which cuts sorted keys with common prefixes by 60–80%. A key-offset table at the head of each leaf gives O(1) access to any key during binary search without walking the variable-length keys. Delta sequence encoding stores each entry’s sequence as a small signed delta from the node’s minimum, and TTLs use zigzag encoding. Internal child offsets are likewise stored as small signed deltas from a base. The two node layouts are:
Leaf node format
[type:1][num_entries:varint][prev_offset:8][next_offset:8][key_offsets_table: num_entries × 2 bytes][base_seq:varint][entries: prefix_len:varint, suffix_len:varint, value_size:varint, vlog_offset:varint, seq_delta:signed_varint, ttl:signed_varint, flags:1][keys: prefix-compressed suffixes][values: inline values only]Internal node format
[type:1][num_keys:varint][base_offset:8][child_offset_deltas: signed_varint × (num_keys + 1)][key_sizes: varint × num_keys][separator_keys: raw key bytes]Internal Components
The engine is assembled from reusable, separately tested modules, each solving one problem behind a clean interface. Having seen how they are used, we can now describe what they are.
Block Manager
The block manager is the lock-free, append-only file abstraction beneath all persistent storage — WALs, key logs, and value logs alike. Each file opens with an 8-byte header (3-byte magic “TDB”, a version, padding). Each block is a header (4-byte size, 4-byte xxHash32 checksum), the data, and a footer (the size again, plus a 4-byte magic “BTDB” for fast backward validation).
Writers use positioned pread/pwrite, so reads and writes proceed without locks, and a block write combines its header, data, and footer into one scatter-gather syscall, cutting three syscalls to one and lifting write throughput 2–2.5×. These calls are abstracted through compat.h; file size is tracked atomically in memory to avoid a syscall; and blocks are reference-counted, freed at zero.
A second, subtler contention point lives inside the kernel: filesystems take a per-inode write lock on any operation that advances the file’s end (ext4’s i_rwsem, APFS’s vnode lock, NTFS’s extension lock), which serializes many threads appending to one file no matter how cleanly userland hands out offsets. To keep the kernel out of the way, the block manager preallocates the file in 64MB chunks ahead of writes, through a cross-platform helper, so ordinary writes land inside the already-extended end and take only the cheaper read path on the inode lock. The extension is itself lock-free — a compare-and-swap claims the right to extend, and a racing claimant at worst issues a redundant, idempotent preallocation — and a clean close truncates the file back to its real data, so the trailing zeros exist only while it is open. After a crash, validation tells a legitimate preallocation tail (an all-zero suffix) from real corruption (non-zero garbage past the data) by combining a forward scan with a trailing-zero check. This buys 1.6–2× higher multi-writer throughput on the small-block WAL workload, at the cost of one preallocation chunk of space per open file (zero at rest).
A read is two preads — one for the 8-byte header, one for the payload into a reusable per-thread buffer — and the checksum is verified in that buffer before any final allocation, so a block that fails verification never costs a heap allocation. A fused read-and-advance avoids a redundant header read, and cursors cache block sizes to skip the size lookup when valid. That cached size has a strict contract: it is always the on-disk (compressed) size, because the cursor advances by header plus that size plus footer; a caller working with decompressed bytes must either set it from the on-disk block or invalidate it, never write the decompressed size back, on pain of advancing into the middle of the next block.
The read path never trusts the 4-byte size field blindly. Before allocating, it computes the block’s full extent and rejects any size whose block would run past the file’s data — the signature of a stale offset, a torn write, or corruption — returning a structured diagnostic rather than allocating from garbage. For unusually large blocks it additionally refuses any size beyond a memory-safety budget derived from the database memory limit; the check is a single relaxed atomic load, so small blocks pay nothing and the hot path makes no syscall. This turns a cursor landing at a bad offset from a crash (or, on a 32-bit host, an out-of-memory) into a graceful read failure. (An earlier fixed 256MB ceiling wrongly rejected the legitimately large bloom blocks of very large bottom-level SSTables, silently disabling their filters on reopen; the extent- and budget-relative checks accept any block that fits both the file and the budget while still catching absurd sizes.)
The layered corruption defenses are the reason the engine can trust what it reads. A per-block xxHash32 checksum is recomputed on every read and fails the read on mismatch. The size is stored twice, so a single-bit flip in one copy is caught by cross-validation. The footer magic is a high-entropy sentinel whose absence reliably marks a torn write. Permissive validation uses these to walk forward through a WAL and truncate at the first inconsistency, distinguishing a partial write (no footer magic) from genuine corruption (footer present, checksum fails). SSTables inherit all of this directly, and WAL entries add bounds-checked deserialization on top, so even a corrupt entry that somehow passed the block checksum fails to load rather than poisoning the memtable.
Bloom Filter
The bloom filter is a packed bitset queried by several hash functions, sized from the target false-positive rate and expected key count by the standard formulas. It serializes with varint headers and sparse encoding — storing only the non-zero words with their indices — which saves 70–90% at the low fill rates typical in practice. Hashing uses Kirsch-Mitzenmacher double hashing: two base hashes are computed and finalized with a murmur3 avalanche step, and the i-th bit position is derived as h1 + i·h2, giving many independent positions from two computations, each mapped to a bit with Lemire’s fast range reduction. The hash is versioned: a filter records which hash built it and is always queried with that same one, so tables written before the avalanche step was added keep using the original hash and never produce a false negative, while new tables get the lower false-positive rate — and the improvement spreads naturally as compaction rewrites old files into new ones. One filter is built per SSTable, written after the data blocks, checked before the block index on reads, and kept resident once loaded.
Clock Cache
The clock cache is a partitioned, lock-free cache pairing a hash index with CLOCK eviction. It divides into many partitions (default 4 per core), each with its own clock hand and index, so contention falls with the partition count. On multi-CCX processors it reads the L3 topology and routes a key to a partition local to the calling thread’s cache group, caching the group in thread-local storage and re-probing periodically to catch thread migration; on a single die or a non-Linux platform this degrades to a plain hash. The partition struct is laid out across cache lines to avoid false sharing — read-only fields on one line, writer atomics on another, reader counters on a third. Entries use atomic state machines, and a single field doubles as the CLOCK recently-used bit (its low bit) and an active-reader count (its upper bits). Gets are fully lock-free, with prefetching to overlap memory latency; puts claim a slot through the clock sweep from a thread-local start position. Eviction gives a recently-used entry a second chance and checks the reader count twice — before clearing pointers and again before freeing — reverting if a reader appeared in between. A zero-copy get returns a pointer into the cached bytes, protected from eviction by the reader count until released.
When a block cache is configured, the engine builds two independent clock caches: one for raw (decompressed but not deserialized) key-log block bytes, keyed by family, file, and offset; and one for fully deserialized B+tree nodes. Caching raw bytes makes block entries about 20× smaller than caching deserialized ones, which sharply raises the hit rate (87% versus under 4% in one 64MB-cache-over-80MB-dataset measurement). A block-cache hit pins the decompressed bytes and lets the caller deserialize from them; a B+tree hit returns the node directly with no I/O; and closing an SSTable invalidates its nodes by prefix.
Skip List
The skip list is the lock-free, multi-versioned ordered map behind every memtable. Each key holds a chain of versions, newest first, each carrying a sequence number, value, TTL, and tombstone flag; probabilistic leveling gives O(log n) search. Inserts are optimistic — traverse, build the node, then compare-and-swap the forward pointers, retrying from the start on a lost race — and the hot path uses stack-allocated scratch for any practical level count. A skip list can be backed by a lock-free bump arena that hands out nodes from contiguous blocks via a non-atomic per-thread pointer bump, making individual frees no-ops and reclaiming everything in bulk when the arena is destroyed; this packs nodes sequentially for locality and is ideal for a memtable that is filled, flushed, and freed whole. New writes prepend a version by compare-and-swap; readers walk the chain for the version matching their snapshot; a tombstone is just a version with the deleted flag. Nodes store forward and backward pointers in one array, giving O(1) access to the last key through the tail sentinel. A skip list can also be given a pointer to an externally cached clock value to avoid repeated time syscalls during TTL checks, and it supports pluggable comparators — which is exactly what lets different column families order keys differently.
Queue
The work queues are thread-safe FIFOs with separate head and tail locks (so enqueue and dequeue rarely contend), an atomic size for lock-free size checks, and a small free list of reusable nodes to cut allocation churn under load. A blocking dequeue lets idle workers sleep on a condition variable rather than spin, and a shutdown flag wakes them to exit cleanly. The flush and compaction pools are driven by exactly these queues.
Manifest
The manifest is the per-column-family record of which SSTables exist at which level, kept as simple text under a reader-writer lock — one line per SSTable (level,id,num_entries,size_bytes), behind a version header and a global sequence. It holds an in-memory array that doubles as it grows; lookups are linear, which is fine because the count per family is rarely over a thousand and manifest writes happen only at flush and compaction. A commit writes a temp file, fsyncs, and renames over the original, so the manifest is always wholly old or wholly new, never partial. During recovery it is the authority on durability: a local restart deletes any SSTable the manifest does not list as an incomplete write, and an object-store cold start rebuilds level membership directly from it.
Platform Compatibility
compat.h isolates every platform difference so the core never has to. Positioned I/O and fdatasync map to their Windows equivalents; atomics use C11 or the older Interlocked intrinsics; threading is pthreads (native or shimmed); directory walking, semaphores, and type and format-specifier differences are all hidden behind it; and performance hints compile to the right intrinsics where they exist. Every source file includes it first, and it has zero runtime overhead — every macro and inline resolves to a native call. It is what lets one codebase run on Windows, macOS, Linux, the BSDs, and Solaris/Illumos unchanged.
Object Store Mode
Everything so far assumed local disk. Object store mode is an optional layer that keeps the durable copy of the data in a remote object store — S3, MinIO, GCS, or any S3-compatible service — and treats local disk as a cache in front of it. This is what enables cloud-native deployments that separate compute from storage: a node can be replaced, and a fresh one rebuilds its working set from the store. Object store mode runs on top of unified memtable mode (enabling it automatically if it is not already on) and is activated by setting a connector on the configuration.
The Connector
Access to the store sits behind a small connector interface: nine operations (put, get, range-get, delete, exists, list, a conditional put and a metadata head added for single-writer fencing, and destroy) and an opaque context for credentials. Connectors must be thread-safe, and the backend is identified by an enum rather than a string so an invalid configuration fails at compile time. Two ship with the engine: a filesystem connector that writes objects as files under a directory (useful for testing and local replication), and an S3 connector that signs requests with SigV4 and works against AWS, MinIO, and compatible endpoints. Object keys are path-like strings derived from each file’s path relative to the database directory.
Two Physical Tiers, Four Access States
Files live across two physical tiers (Figure 8). The local tier is the database directory on disk, where all writes, flushes, and compactions produce files exactly as in non-object-store mode. The remote tier is the object store, to which files are uploaded after creation and from which they are fetched when absent locally.
A key-value pair moves through these tiers in order. It starts in the shared memtable, backed by the unified WAL on local disk, which the reaper periodically syncs to the store by write volume. When the memtable freezes, a flush worker demuxes it into per-CF SSTables on local disk — identical to non-object-store mode — and then synchronously uploads each key log and value log, so the store has a copy before local eviction could ever delete one (the manifest is published separately, under the single-writer fence described below). The files then live on as cache entries, promoted to the head of an LRU list on every access. When a local-cache size limit is set and new files push past it, the least-recently-used files are evicted from disk — a key log and its value log always together — while the copies in the store remain. A later read of an evicted table fetches what it needs from the store; a compaction downloads its evicted inputs, writes and uploads the merged output, and deletes the inputs from both tiers.
Layered over those two physical tiers is a finer access hierarchy that classifies data by how fast a read of it will be. Hot data is the active memtable and the block cache — served from memory with no I/O. Warm data is SSTables whose files are local and whose block managers are open — served at page-cache or NVMe speed. Cold data is local files whose block managers the reaper has closed to bound descriptors — a read reopens them, a local operation with no network. Frozen data has been evicted from disk but remains in the store — a point lookup fetches just the one block it needs over a single HTTP range request and caches it straight into the hot tier, while an iterator prefetches whole files in parallel and lands them warm. Data flows downward through these states as it ages, and the system is self-tuning: frequently read tables stay promoted automatically through LRU touches and cache hits, while the store provides an effectively unlimited capacity floor.
How the Paths Change
The write path is unchanged in memory and in the WAL; only the flush adds remote work — a synchronous, retried upload of each SSTable after it is written locally, a fenced manifest publish (synchronous when fencing is active, so it can re-assert the primary lease; see below), and (when WAL replication is on) an upload of each closed WAL segment before it is deleted. An upload that exhausts its fast retries is not dropped: it is parked into a deferred backlog that the reaper re-attempts on a slow, capped backoff, so even a multi-minute store outage still delivers once it clears. Until its upload confirms, an SSTable stays untracked and therefore unevictable, so a failed upload can never let a file be reclaimed off local disk before it has landed remotely. Rotated WAL segments and manifests defer the same way; the active-WAL snapshot is the exception, since its periodic resync re-ships it anyway and parking a stale snapshot could overwrite a newer one. The S3 connector keeps its memory bounded on large files by switching from a single streaming PUT to a multipart upload above 64MB, streaming the file in fixed 8MB parts and aborting cleanly on any failure so no orphaned parts linger; the connector never holds more than one part in memory, and the multipart path lifts the single-object ceiling well past S3’s single-PUT limit.
The read path diverges only for a frozen SSTable. A point lookup runs its bloom and block-index checks on the always-resident in-memory metadata, rejecting most tables with no I/O, and on a definitive index hit for a non-local file it fetches exactly one block (~64KB) over one range request, verifies and decompresses it, and caches it so later lookups in that block are pure memory hits; a value in the value log costs two more range requests, one for its header and one for the data. An iterator instead prefetches every non-local file it will need in parallel, bounded by a download-concurrency limit, so prefetch time is set by the largest file plus network latency rather than the sum of all files. If a range request fails or the index is not precise enough, the read falls back to downloading the whole file with retries, checking existence first so a fresh local SSTable whose object does not exist remotely yet is not chased pointlessly.
Compaction operates on local files with remote work only at the edges: it prefetches evicted inputs in parallel (by default), writes and uploads the merged output, and commits and uploads the manifest before deleting the old inputs, so replicas and cold-start nodes always see the new table before the old ones vanish. A lazy-compaction option doubles the level-1 trigger to trade read amplification for less remote I/O.
Cold Start, WAL Sync, and Replication
A node starting with an empty local directory but a configured store recovers by first pulling the root UNIMAP (so column-family indexes are right before anything opens), then listing the store, identifying families by their manifests, and downloading each family’s config and manifest in parallel. It reconstructs the SSTable inventory and metadata in memory and leaves the data in the store until queries ask for it, so cold-start time tracks network latency, not data volume.
The reaper syncs the active WAL to the store by write volume, not wall clock: each cycle it checks how much the WAL has grown and, past a threshold (wal_sync_threshold_bytes, default 1MB), enqueues an upload. No syncs happen while idle; they fire often during bursts. Since the WAL is append-only, uploading a snapshot mid-write is safe, and recovery replays it normally. A WAL upload ships only the log’s logical length, not the 64MB the block manager preallocates ahead of it, so even a per-commit sync is a small write rather than a full-file transfer. This bounds the crash data-loss window to the configured byte threshold rather than a whole flush cycle. Separately, when WAL replication is enabled (the default), closed segments are uploaded after flush so another node can recover uncommitted data by replaying them, with a flag choosing whether the upload blocks the flush path for stronger durability or runs in the background for lower latency.
Replicas, Promotion, and Failure
A read-only replica follows a primary through the store. It is enabled with a flag; in replica mode writes return TDB_ERR_READONLY immediately while reads work normally, using the same isolation levels, iterators, and caches as the primary. Before each sync the replica re-downloads UNIMAP so it picks up any family the primary added, dropped, or renamed — and, because it loads first, the replica’s new families adopt the primary’s indexes, the only way WAL prefixes can resolve to the right families. It then polls each family’s remote manifest (default every 5 seconds), diffs it against the local one, and adds or drops SSTables to match, fetching data on demand rather than during the sync. With WAL replay on (the default), it also discovers and replays new WAL segments in generation order, idempotently — entries below the current maximum are skipped, and the skip list rejects any duplicate key-sequence pair — so the replica sees writes the primary committed but has not yet flushed, even across several WAL generations. Its memtable is ephemeral, rebuilt from the primary’s segments each cycle. For tighter lag the primary can upload the WAL synchronously on every commit (wal_sync_on_commit), at the cost of one HTTP round-trip per commit, bounding the replica’s lag to roughly the sync interval.
Promotion turns a replica into a primary, and its first act is to claim the bucket. It verifies the store still enforces conditional writes, then acquires the primary lease by advancing its epoch with a conditional, compare-and-swap write; if another node has already taken the lease the acquire fails and promotion is refused with TDB_ERR_PRECONDITION, leaving the node a working replica for the orchestrator to retry. Holding the lease, it stops and joins the sync thread, runs one final manifest sync and WAL replay — gated on the outgoing primary’s epoch, so that primary’s last writes are absorbed rather than skipped as stale against the new epoch — creates a local WAL for new writes, and only then atomically clears replica mode. Because the replica already holds the manifest and metadata in memory, the catch-up is a final WAL download and replay plus a file creation, milliseconds of work; the decision of when to promote is still left to an external orchestration layer, but the lease is what makes that decision safe to act on even when the old primary is slow to die.
The concurrency model is unchanged within a node: many threads commit concurrently with full MVCC, flush and compaction run in parallel, and the upload pipeline is itself multi-threaded. Single-writer is a bucket-level invariant — two nodes writing one bucket would otherwise produce conflicting manifests, colliding SSTable IDs, and racing deletes — and the engine enforces it directly rather than trusting the orchestrator to. The primary holds a lease object in the bucket whose epoch it advances with a conditional compare-and-swap write, and every manifest publish re-asserts that lease before it writes. If a superseded primary — one that lost the role but is still alive and can still reach the store, the case an external lease or STONITH cannot fully rule out — tries to publish, its lease re-assertion fails the precondition and it self-demotes to a replica instead of writing. Manifests and WAL segments carry the epoch that wrote them, and every reader (replica sync, cold start, WAL replay) ignores any object whose epoch is below the current lease, so even an object a fenced node uploads before it notices is never honored. The protection is contingent on the store actually enforcing conditional writes: a probe at startup checks this, and if the backend does not, fencing is disabled and logged, falling back to the orchestrator-honored invariant. On a clean shutdown the engine flushes everything and drains all uploads before exiting, so there is no loss. On a crash the loss window is exactly the WAL-sync configuration: zero with sync-on-commit, the byte threshold with periodic sync, a full flush cycle if periodic sync is disabled. Recovery without a replica follows the cold-start path; recovery with a warm replica is a promotion. Upload failures are surfaced through a stats counter and the shutdown log and retried from the deferred backlog until they land, so a transient outage costs latency rather than data; download failures after all retries propagate as read errors; and at shutdown the upload pipeline broadcasts a wake to every worker so threads terminate promptly on every platform.
Testing and Quality Assurance
TidesDB is tested with CI automation across more than 15 platform and architecture combinations. Every internal module has its own test file — block manager, skip list, bloom filter, and the rest — with unit tests, integration tests, and benchmarks, and a main suite exercises the whole database lifecycle: basic operations, transactions at every isolation level, persistence, WAL recovery, every compaction strategy, iterators, TTL, compression, bloom filters, block indexes, concurrency, edge cases, and stress. The test harness takes an optional substring filter, so any binary can run a named subset.
The build adapts itself to Linux, macOS, Windows (both MSVC and MinGW under MSYS2), the BSDs, and Solaris/Illumos, detecting the platform and, on macOS, Intel versus Apple Silicon. The CI exercises an architecture matrix of x64, x86, PowerPC, and RISC-V, supplying the cross-compilation toolchains; it manages dependencies per platform, enables sanitizers on Unix, and registers everything with CTest. The installed library carries a soname and follows each OS’s install conventions, so packagers need no per-distro patches.
A few details show the breadth of coverage. PowerPC is built and verified on both its targets, but how far the tests run depends on the target: the macOS PowerPC build stops at build verification, because Mach-O PowerPC binaries have no execution path on the Linux CI hosts, while the Linux PowerPC build additionally runs its tests best-effort under QEMU, where emulating PowerPC pthreads and atomics is unreliable enough that a failure is logged rather than failing the build. MinGW runs one code path for both x64 and x86, building Snappy from source because the prebuilts were dropped, and resolving zstd and lz4 through the package files MSYS2 does ship. Most tellingly, a portability test creates a database on Linux x64, ships it as an artifact, and reads every key back correctly on seven different platforms — direct proof that the on-disk format is portable across architectures and endianness.
Object storage and replication carry their own workflows. The store itself is exercised against MinIO, and failover is tested at two fidelities. A fast, dependency-free workflow runs real node processes that share a filesystem bucket on the CI runner — the filesystem connector takes a flock, so the single-writer fence holds across processes — and drives clean failover with promotion catch-up, the fencing of a still-alive old primary that self-demotes the moment it next tries to publish, and zero-RPO recovery of writes that were acknowledged but never flushed. A heavier cloud simulation stands up a Kubernetes cluster with kind, a real MinIO bucket, and the node running one per pod, so the fence is exercised over genuine S3 conditional writes rather than the filesystem shortcut: it covers fan-out replication to several replicas, a primary failure that the surviving replicas re-follow onto the newly promoted node, the fencing of a primary that is network-partitioned from the bucket and self-demotes when it reconnects to find it has been superseded, and cascading failovers in which the lease epoch advances monotonically across each promotion.
Together this infrastructure is what keeps the engine correct, fast, and portable across every platform it claims to support.